FASTAI
1.快速入门
安装库
pip install fastai
导入库
from fastai.vision.all import *
from fastai.text.all import *
from fastai.collab import *
from fastai.tabular.all import *
1.1图片分类–> 猫图片预测
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(1)
分析结果
#查看 top8 loss
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses(k=8)

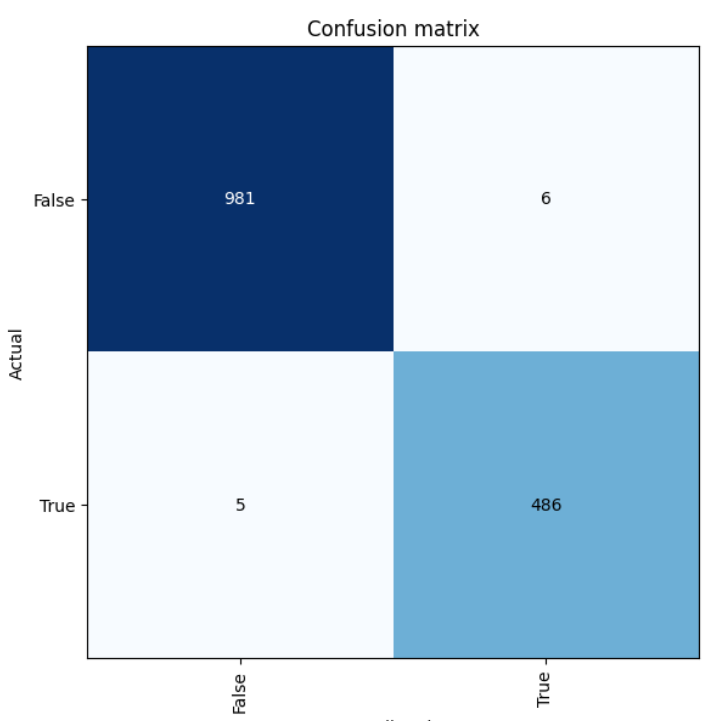
#查看cnfusion_matrix
interp.plot_confusion_matrix(figsize=(6,6))
1.2 分析代码
path = untar_data(URLs.PETS)
下载数据,返回数据集所在目录
files = get_image_files(path/"images")
获取path目录下/images文件
def label_func(f): return f[0].isupper()
数据处理函数,如果f的第一个字母为大写,则返回True,用到的数据集中首字母大写的为猫。
dls = ImageDataLoaders.from_name_func(path, files, label_func, item_tfms=Resize(224))
path为数据集路径,files为具体文件路径,label_func为对files进行的处理作为标签,item_tfms为图片的处理。
learn = vision_learner(dls, resnet34, metrics=error_rate)learn.fine_tune(1)
使用数据集进行训练。
learn.predict(Path(r"C:\Users\qwrdxer\Pictures\Abyssinian_1.jpg"))
将图片地址转换为Path类型进行预测
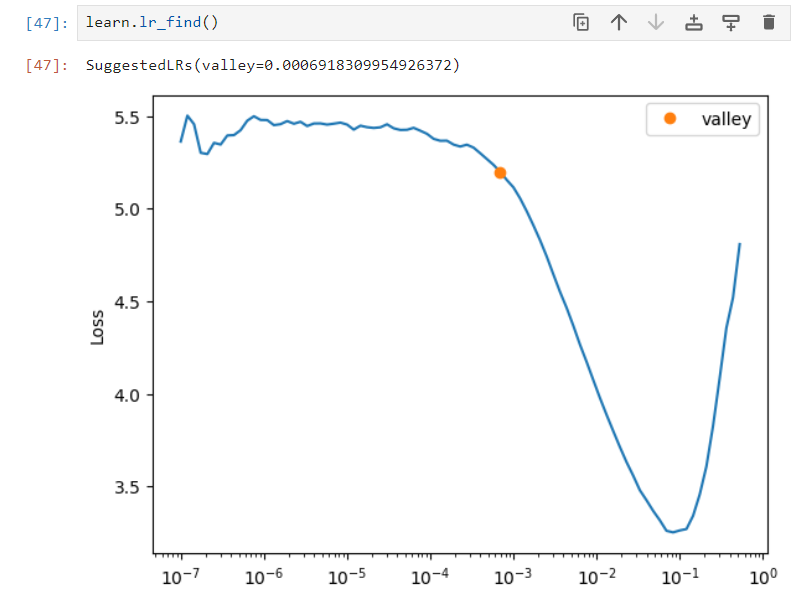
使用lr_find来查找合适的学习率
2.进阶dataloader
2.1 示例
pets = DataBlock(blocks=(ImageBlock, CategoryBlock), #用到的类型,图片、分类
get_items=get_image_files, #获取x的方式
splitter=RandomSplitter(), #分割方式
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'), #获取y标签的方法
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224))
A datablock is built by giving the fastai library a bunch of informations:
- the types used, through an argument called
blocks: here we have images and categories, so we passImageBlockandCategoryBlock. - how to get the raw items, here our function
get_image_files. - how to label those items, here with the same regular expression as before.
- how to split those items, here with a random splitter.
- the
item_tfmsandbatch_tfmslike before.
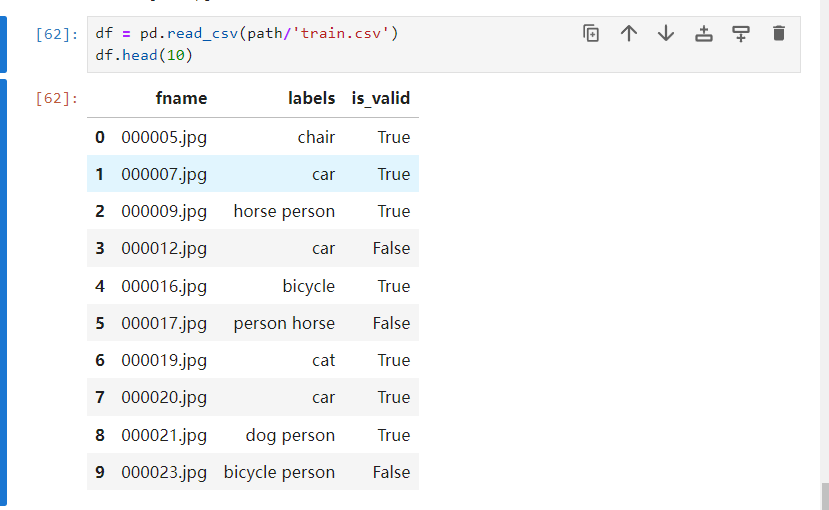
2.2 通过csv格式文件 进行标签
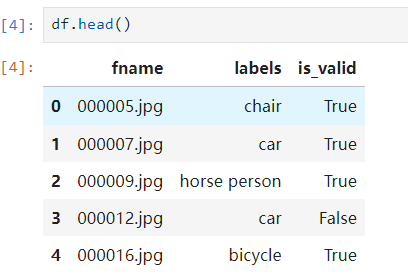
例子使用了多分类的数据集,标签在train.csv中
dls = ImageDataLoaders.from_df(df, path, folder=’train’, valid_col=’is_valid’, label_delim=' ', item_tfms=Resize(460), batch_tfms=aug_transforms(size=224))
使用from_df函数来加载csv的数据集。
path为基目录,folder 用于在path和filename之间增加路径path/folder/filename
label_delim 指定使用空格作为标签分类条件
文件名、标签默认为第一二列所以这里不需要指定。
进阶:
pascal = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=ColSplitter('is_valid'),
get_x=ColReader('fname', pref=str(path/'train') + os.path.sep),
get_y=ColReader('labels', label_delim=' '),
item_tfms = Resize(460),
batch_tfms=aug_transforms(size=224))
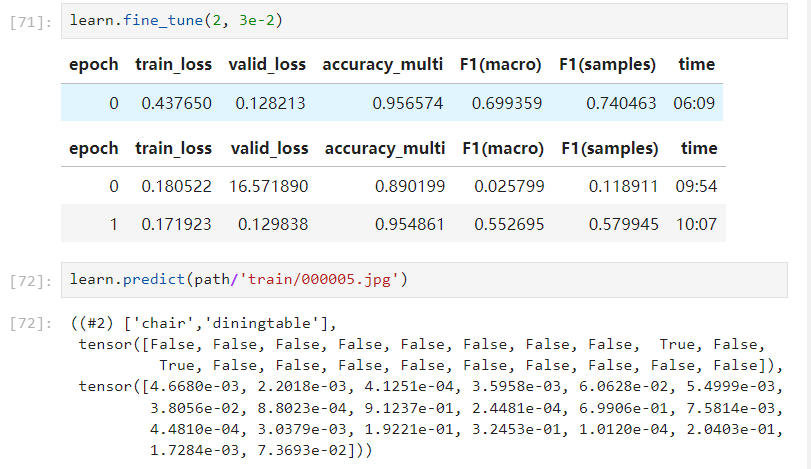
多分类使用F1 Score来评价模型的好坏
f1_macro = F1ScoreMulti(thresh=0.5, average='macro')
f1_macro.name = 'F1(macro)'
f1_samples = F1ScoreMulti(thresh=0.5, average='samples')
f1_samples.name = 'F1(samples)'
learn = vision_learner(dls, resnet50, metrics=[partial(accuracy_multi, thresh=0.5), f1_macro, f1_samples])
3. 进阶DataBlock
3.1 从头开始创建一个DataBlock
DataBlock 可以理解为一个如何汇聚数据的模板,我们可以通过DataBlock的实例的
datasets方法获取数据集、dataloaders方法来获取 Dataloader进行训练、summary方法来看数据集的构造细节。
下面的示例代码中创建了一个空的DataBlock,然后将文件名作为数据集传入其中,随后输出数据集的第一个。
from fastai.data.all import *
from fastai.vision.all import *
path = untar_data(URLs.PETS)
fnames = get_image_files(path/"images")# 下面的代码中使用get_items可以直接指定。
dblock = DataBlock()#创建一个空的DataBlock
dsets = dblock.datasets(fnames)
dsets.train[0]

默认情况下DataBlock对数据集的处理包含输入(X)和输出(Y),因为这里没做任何处理,所以打印出来2次重复的。
首先我们可以指定
get_items来确定如何获取数据集(X)。
dblock = DataBlock(get_items = get_image_files)
随后是如何获取标签值(Y)
观察数据集可知,文件名如果是大写英文开头,则为猫,小写则为狗,我们可以根据这种规则来对数据打标签,下面使用label_func函数来实现。
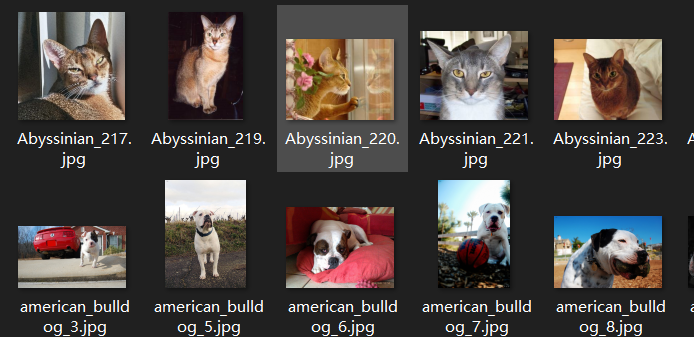
def label_func(fname):
return "cat" if fname.name[0].isupper() else "dog"
dblock = DataBlock(get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path/"images")
dsets.train[0]
可以看到train[0] 已经可以正常输出X,Y了(注意X虽然是路径,但框架可以很方便的通过这个完整的文件路径来获取图片)
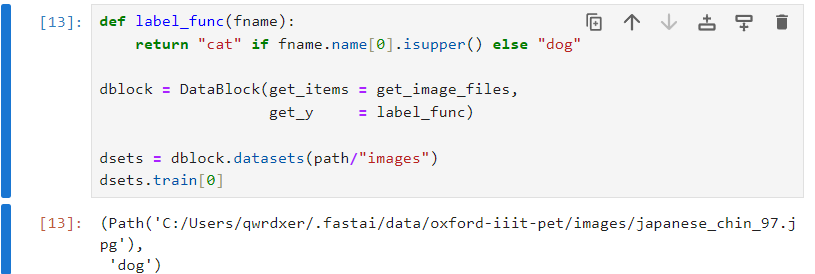
我们现在知道了输入是图片(Images),输出是类别(Category), 我们可以通过blocks来制定输入和输出的类型。
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path/"images")
dsets.train[0]
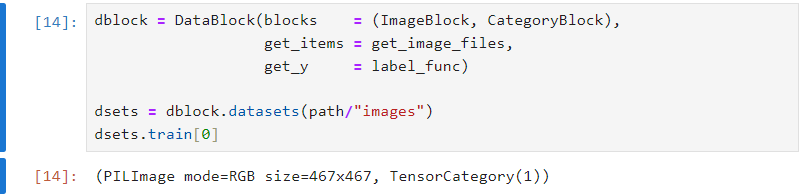
这样的输出的train[0]就更为简单易懂了,输入为RGB图片,输出为类别下标1,我们可以通过dsets.vocab 来获取类别,这里1代表dog

接下来的是一些进一步的优化和展示。
splitter 表示对数据集中验证集的划分,这里是随机划分。
item_tfms 代表对X的处理,这里将他们的size都设置为224x224
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func,
splitter = RandomSplitter(),
item_tfms = Resize(224))
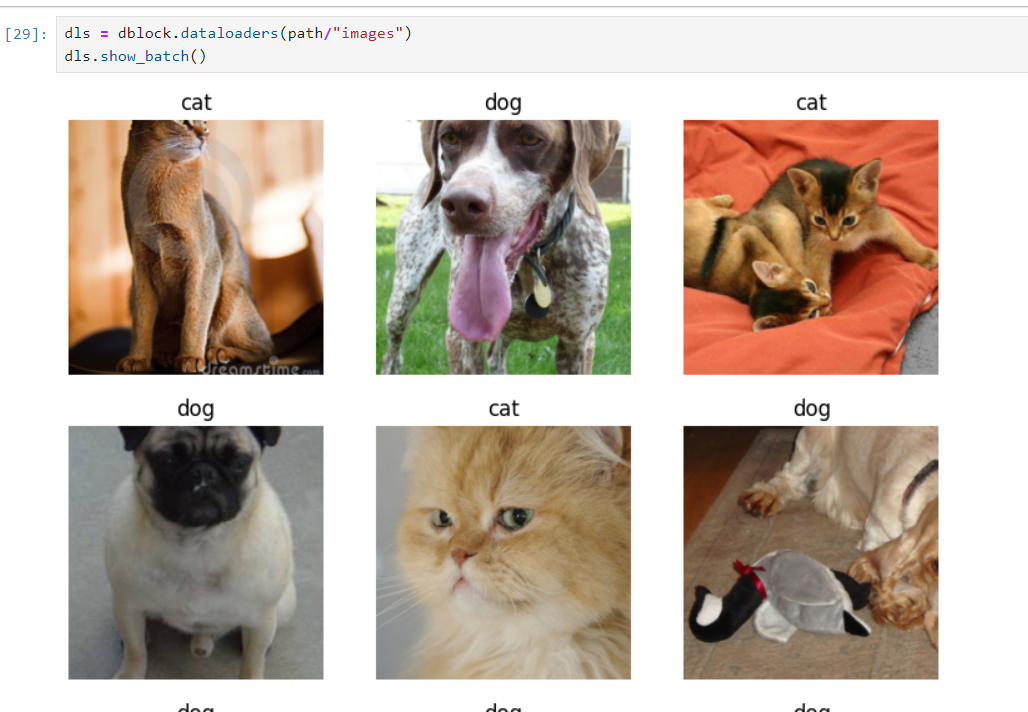
使用show_bach可以方便的查看数据集
dls = dblock.dataloaders(path/"images")
dls.show_batch()
总结一下,我们可以通过回答下列的问题来构建一个datablock:
- 输入(X)/目标(Y)的类型分别是什么? 上文例子中为 图片/类别。
- 数据在哪里? 这里的输入来自一个文件夹
- 有无必要在数据输入时做一些处理?这里没有做任何处理
- 有无必要对目标(Y)做一些处理?这里 使用
label_func - 如何划分训练集和验证集?这里使用的是随机划分。
- 需要对样本进行格式统一操作吗? 这里图片大小不一致,使用
resize进行调整。 - 需要对batches进行统一处理吗? 这里不需要。
3.2 MINST数据集
接下来将使用MNIST_TINY手写数据集进行学习,这个数据集中包含一些数字3和7的手写图片
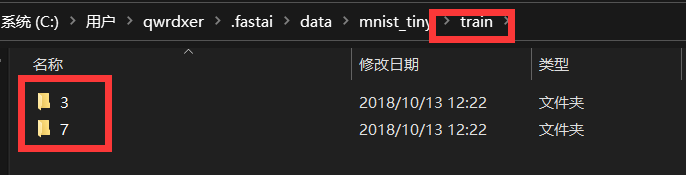
首先看一下要使用的数据集目录结构, mnist_tiny下已经划分好了训练集验证集和测试集。
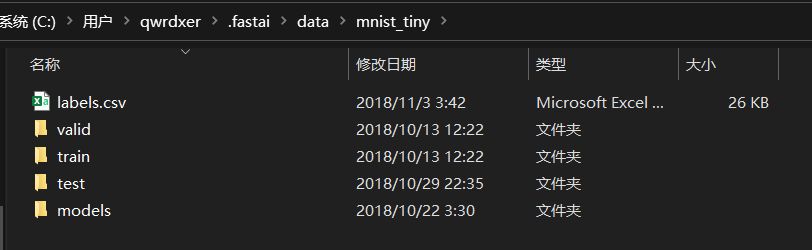
三个数据集目录下有两个子目录3 和7 代表两个数字的图片集。
如何构建DataBlock?
首先,输入的图片并不是RGB图片而是黑白图片,因此要指定ImageBlock的类别为 cls=PILImageBW。
如何获取图片标签? 这里图片所在的目录即为类别,可以通过get_y=parent_label来获取。
如何划分数据集? 这里数据集已经分好类了,图片的上两级目录(grandparent ,或者说父目录的父目录)即为不同的数据集splitter=GrandparentSplitter()。
如一张图片目录为 train/3/9932.png , 其parent 即为3,其grandparent即为train。
mnist = DataBlock(blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter(),
get_y=parent_label)
构造完成后,可以查看一下具体的内容
dls = mnist.dataloaders(untar_data(URLs.MNIST_TINY))
dls.show_batch(max_n=9, figsize=(4,4))

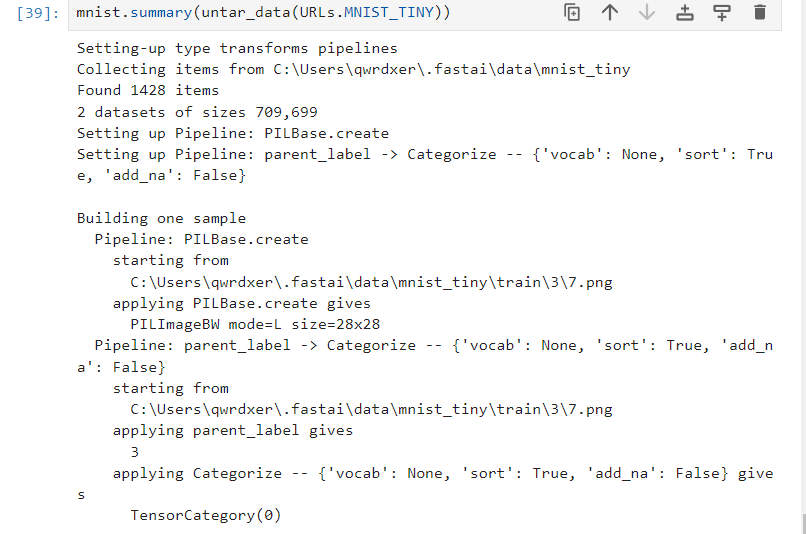
也可以通过summary看看构造的具体过程
3.4 Oxford IIIT Pets dataset 数据集(多分类+标签处理)
我们一开始用的数据集就是这个,不过刚才只关注猫狗的二分类,实际上这个数据集 共有37种不同的类别。
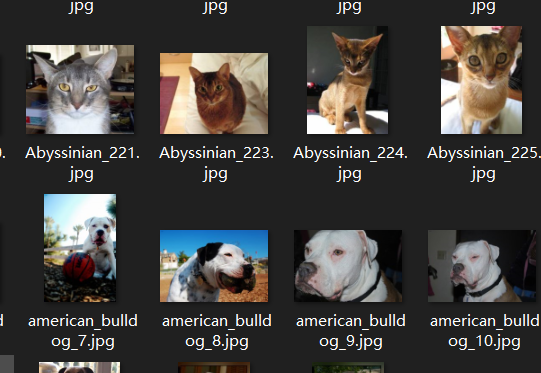
图片的格式为 品种_序号.jpg ,其中品种可能有多个单词,也使用 _ 进行分割。大小写分别代表猫和狗。
如何构造DataBlock?
比较难的点在于获取标签,使用如下代码来获取
get_y=Pipeline([attrgetter("name"), RegexLabeller(pat = r'^(.*)_\d+.jpg$')]),
首先调用artrgetter来获取 输入的Path 的name的值(即文件名)。
然后调用RegexLabeller(正则匹配)对这个值进行处理,最后获取类别。
最后使用PipeLine方法来将这两个处理合并。
pets = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=Pipeline([attrgetter("name"), RegexLabeller(pat = r'^(.*)_\d+.jpg$')]),
item_tfms=Resize(128),
batch_tfms=aug_transforms())
3.5 Pascal (多标签分类)
加载
pascal_source = untar_data(URLs.PASCAL_2007)
df = pd.read_csv(pascal_source/"train.csv")
图片中可能有多个标签(如骑马的图片中会有人 和马的标签)
如何构造DataBlock?
这里对DataBlock输入的是一个csv文件,我们可以根据其每行的数据来构造数据集。
pascal = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=ColSplitter(),
get_x=ColReader(0, pref=pascal_source/"train"),
get_y=ColReader(1, label_delim=' '),
item_tfms=Resize(224),
batch_tfms=aug_transforms())
dls = pascal.dataloaders(df)
dls.show_batch()
通过 get_y=ColReader(1, label_delim=' '),的label_delim来设置按空格分隔。
pascal = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=ColSplitter(),
get_x=lambda x:pascal_source/"train"/f'{x[0]}',
get_y=lambda x:x[1].split(' '),
item_tfms=Resize(224),
batch_tfms=aug_transforms())
通过使用lambda 表达式来更简洁的进行分割。
def _pascal_items(x): return (
f'{pascal_source}/train/'+x.fname, x.labels.str.split())
valid_idx = df[df['is_valid']].index.values
pascal = DataBlock.from_columns(blocks=(ImageBlock, MultiCategoryBlock),
get_items=_pascal_items,
splitter=IndexSplitter(valid_idx),
item_tfms=Resize(224),
batch_tfms=aug_transforms())
这个跟前两个不同的是,调用了DataBlock的from_columns方法来构造。
通过使用自定义函数,该函数的输入为csv的行,我们可以根据列名字来访问成员,其返回值为(X,Y)。
通过
df[df['is_valid']].index.values获取了所有is_valid为True的下标用于验证集的划分。

3.6 图片定位
图像定位类别中有各种问题:图像分割(这是一项必须预测图像中每个像素类别的任务)、坐标预测(预测图像上的一个或多个关键点)和目标检测(在要检测的对象周围画一个框)。
图像分割
将图片的所有像素进行分类。首先输入是一张正常的图片,输出则为对图片所有像素分好类的图片。
数据集的(X,Y)如下:

camvid = DataBlock(blocks=(ImageBlock, MaskBlock(codes = np.loadtxt(path/'codes.txt', dtype=str))),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',
batch_tfms=aug_transforms())
首先是MaskBlockMaskBlock(codes = np.loadtxt(path/'codes.txt', dtype=str) 即我们的输出的像素的类别由codes.txt来定义。
获取Y的方法: lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',
图片的文件名为0001TP_006750.png ,输出的文件名为0001TP_006750_P.png ,f’{o.stem}_P{o.suffix} ‘即为
f’{0001TP_006750}_P{.jpg}’
坐标预测
biwi = DataBlock(blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=lambda o:fn2ctr[o.name].flip(0),
batch_tfms=aug_transforms())
get_y=lambda o:fn2ctr[o.name].flip(0) 的作用是根据输入图像文件名,找到相应的目标坐标点,并进行翻转。这样,每个输入图像就有了与之相匹配的目标点,可以用于训练模型。
目标检测
这里使用的是COCO数据集, 它包含日常物品的图片,目的是通过在日常物品周围绘制矩形来预测日常物品的位置。
train.json对应了图片中的物品位置、物品类型
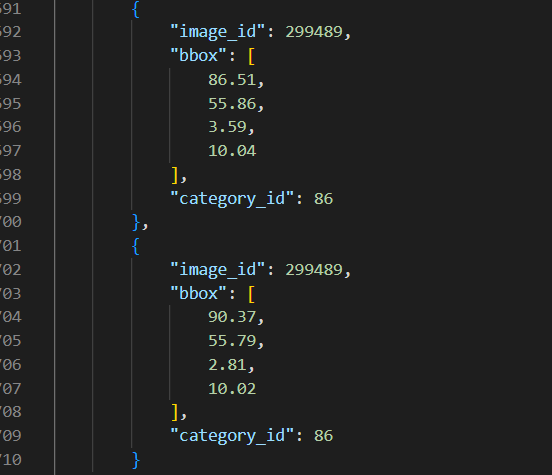
首先将其加载进来
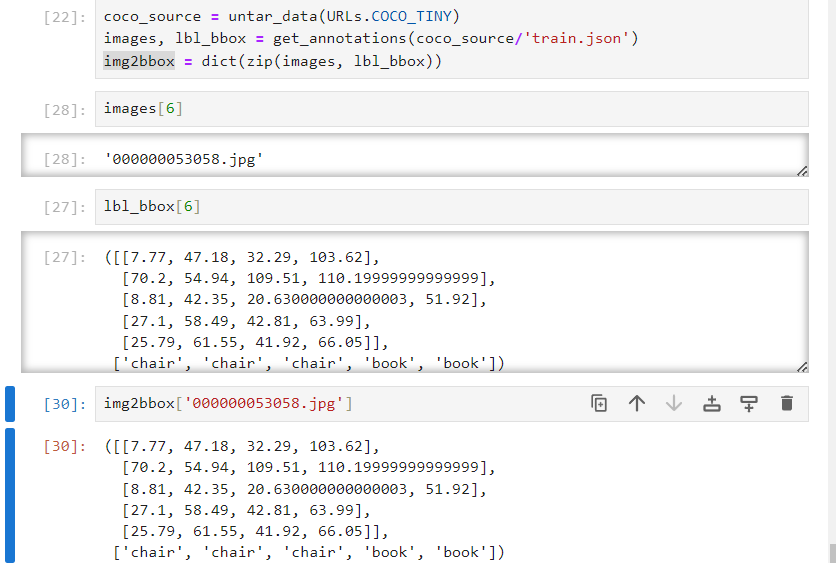
img2bbox就是字典类型,key为文件名,Value就是图片中物品的位置、类型。这个字典后续用于标签的构造。
coco = DataBlock(blocks=(ImageBlock, BBoxBlock, BBoxLblBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=[lambda o: img2bbox[o.name][0], lambda o: img2bbox[o.name][1]],
item_tfms=Resize(128),
batch_tfms=aug_transforms(),
n_inp=1)
在block中有三个block,因为输出有box的坐标和box对应的类别,通过n_inp=1来说明输入截止的block(第一个)。
dls = coco.dataloaders(coco_source)
dls.show_batch(max_n=9)
语言模型
from fastai.text.all import *
path = untar_data(URLs.IMDB_SAMPLE)
df = pd.read_csv(path/'texts.csv')
df.head()
跟其他DataBlock不同的是,输入和输出几乎一致,因此这里只用了一个TextBlock
imdb_lm = DataBlock(blocks=TextBlock.from_df('text', is_lm=True),
get_x=ColReader('text'),
splitter=ColSplitter())
dls = imdb_lm.dataloaders(df, bs=64, seq_len=72)
dls.show_batch(max_n=6)
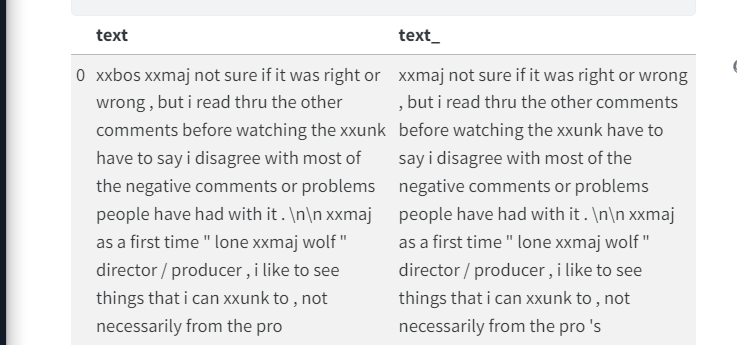
input[x]= output[x-1] ,用于训练预测下一个词,生成 文本。
参考文章
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com