使用不同层次的API加载数据
文档参考: https://docs.fast.ai/tutorial.imagenette.html
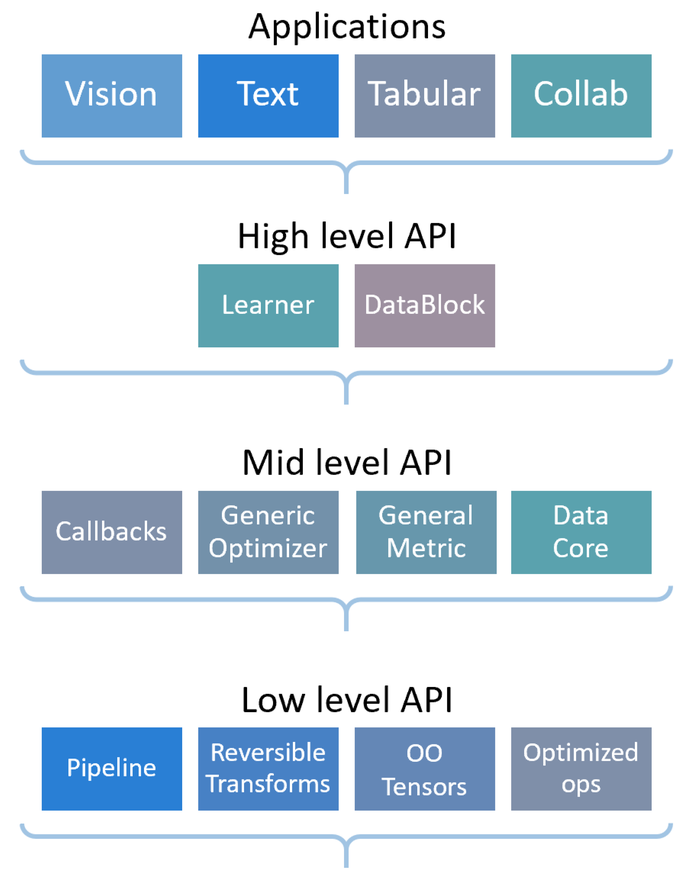
如图所示,FastAI库有不同层次的API供我们使用,高级的API使用方便,低级的API可供我们进行自定义。
在接下来的文章中,我们将使用ImageNette( imagenet的子集,包含10个不同的类别)来讨论不同的数据加载方法,文章的最后将对加载好的数据集进行训练。
我们将在本教程中展示如何使用常见的高级API在上面训练模型,然后深入研究fastai库,向您展示如何使用我们设计的中级API。这样,您就可以根据需要来自定义自己的数据收集或训练。
1.0 数据集介绍
目录如下
train/和val/文件夹分别包含用于训练和验证的图像。- 每个子文件夹(如
n01440764/和n02102040/)代表一个类别,其名称通常是 ImageNet 的 WordNet ID。 - 每个类别文件夹内包含该类别的多个 JPEG 图像。
- 这种文件结构方便于使用各种数据加载工具。
imagenette/
|-- noisy_imagenette.csv
|-- train/
| |-- n01440764/ (这是类别1的标签)
| | |-- img1.jpg
| | |-- img2.jpg
| | |-- ...
| |-- n02102040/ (这是类别2的标签)
| | |-- img1.jpg
| | |-- img2.jpg
| | |-- ...
| |-- ...
|-- val/
| |-- n01440764/
| | |-- img1.jpg
| | |-- img2.jpg
| | |-- ...
| |-- n02102040/
| | |-- img1.jpg
| | |-- img2.jpg
| | |-- ...
| |-- ...
1.1使用Applications层加载数据
from fastai.vision.all import *
path = untar_data(URLs.IMAGENETTE_160) #下载数据集,返回数据集所在目录
dls = ImageDataLoaders.from_folder(path, valid='val',item_tfms=RandomResizedCrop(128,min_scale=0.35),batch_tfms=Normalize.from_stats(*imagenet_stats)) #使用ImageDataLoaders加载数据集
dls.show_batch()
因为高级API的良好封装性,我们只要设置好参数就能很方便的将数据集加载进来。

1.2使用High level API加载数据集
接下来我们将使用DataBlock来构造数据集,构造完成后可以选择使用DataBlock.Datasets或DataBlock.dcataloaders方法将该源转换为数据集或加载器。
首先使用 get_image_files 来获取指定目录下所有图片(的路径)
fnames = get_image_files(path)

我们先用一个不含任何参数的DataBlock
dblock = DataBlock()
dsets = dblock.datasets(fnames)#传入的是get_image_files(path)
dsets.train[0]
默认情况下,DataBlock的API会假设我们有一个输入(X)和一个输出(Y), 由于我们只传入了文件路径,这导致输入 和输出都是文件路径,运行上面的代码输出如下。
(Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03425413/n03425413_7416.JPEG'),
Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03425413/n03425413_7416.JPEG'))
指定输入(X)和输出(Y)
首先我们先处理一下标签, 上文中ImageDataLoader会使用图片的父目录作为标签

我们可以通过设置一个字典结构来将其转换。
lbl_dict = dict(
n01440764='tench',
n02102040='English springer',
n02979186='cassette player',
n03000684='chain saw',
n03028079='church',
n03394916='French horn',
n03417042='garbage truck',
n03425413='gas pump',
n03445777='golf ball',
n03888257='parachute'
)
为了让DataBlock可以使用这个字典我们需要定义一个函数来将其进行转换。
def label_func(fname):
return lbl_dict[parent_label(fname)]
然后我们可以构造DataBlock了
dblock = DataBlock(get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path)#获取加载好的数据集
接下来我们修改向其传入的参数。
get_items 使用了 get_image_files函数,它可以将指定目录 path下的图片路径加载进来,通过路径DataBlock可以很方便的加载图片。
get_y使用了我们自定义的label_func函数,这样我们
我们可以看看这个数据集。
#获取一条训练数据
dsets.train[0]
(PILImage mode=RGB size=187x160, TensorCategory(0))
#获取数据集的标签列表
dsets.vocab
['English springer', 'French horn', 'cassette player', 'chain saw', 'church', 'garbage truck', 'gas pump', 'golf ball', 'parachute', 'tench']
理解get_items和get_y接收的参数(以下是询问CHATGPT的答案)
在 fastai 的 DataBlock API 中,get_y 函数的参数通常是 get_items 函数处理后的单个结果。简单来说,get_items 用于从数据源(例如一个目录、一个数据框(DataFrame)等)中获取所有的项(通常是文件路径),而 get_y 则是用于从单个项(如一个文件路径)来获取对应的标签(或目标值)。
当 fastai 的 DataBlock API 构造一个数据集时,它首先使用 get_items 函数来获取所有的数据项。然后,对于 get_items 返回的每一个单个项,它会使用 get_y 函数来找到相应的标签。
这就是为什么在很多 fastai 的教程或示例代码中,你会看到 get_y 函数通常会处理文件名或文件路径。因为这些文件名或路径就是 get_items 函数返回的结果,现在需要为它们找到对应的标签。
这种模块化的设计使得 fastai 的 DataBlock API 非常灵活,你可以通过简单地替换 get_items 或 get_y 函数来轻松地适应不同类型的数据源或任务。
更进一步处理
我们可以指定验证集的获取方法、图片的预处理方法。
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func,
splitter = GrandparentSplitter(),
item_tfms = RandomResizedCrop(128, min_scale=0.35),
batch_tfms=Normalize.from_stats(*imagenet_stats))
splliter指定训练集和验证集的划分,
item_tfms
- 作用对象:作用于每一个单独的数据项(item)。
- 应用时机:在批处理(batching)之前,即在单个数据项被收集到一个批次之前。
- 常见用途:包括但不限于裁剪(cropping)、调整大小(resizing)、转换为灰度图像(grayscale)等。
- 性能:由于
item_tfms是在批处理之前应用的,因此每个转换都是独立的,这可能会减慢数据加载速度。
例如,如果你想确保每个图像都被调整到相同的大小,你可能会使用 item_tfms。
batch_tfms
- 作用对象:作用于一个整个数据批次(batch)。
- 应用时机:在批处理(batching)之后,即数据已经被整合到一个批次,并准备送入模型之前。
- 常见用途:包括但不限于数据标准化(normalization)、数据增强(如随机旋转、翻转等)。
- 性能:由于操作是在一个整个批次上进行的,通常可以利用 GPU 加速,因此一般而言会更快。
例如,如果你想对整个数据批次进行数据增强,你可以使用 batch_tfms。
1.3 使用mid-level API加载数据集
接下来我们将介绍用于对数据进行处理的transform ,然后自己构造出dataset ,通过Dataset进一步处理来获取用于训练的Dataloader。
Transform
在fastai中,我们对原始项(这里是文件名)应用的每一个转换都被称为Transform。它基本上是一个添加了一些功能的函数:
- 根据接收的类型,它可以有不同的行为(这称为类型调度)
- 它通常应用于元组的每个元素
尝试构建一个Transform
首先是获取所有的文件名。
source = untar_data(URLs.IMAGENETTE_160)
fnames = get_image_files(source)
通过fnames, 我们可以很方便的查看图片
PILImage.create(fnames[0])

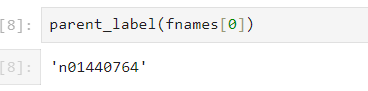
通过parent_label,我们可以获取这个图片的父目录
parent_label(fnames[0])
通过上文构造的字典,可以将实际的标签显示出来
lbl_dict[parent_label(fnames[0])]
'garbage truck'
这一系列的操作可以通过PipeLine进行串行的处理,我们可以自定义个Transform如下:
tfm = Pipeline([parent_label, lbl_dict.__getitem__, Categorize(vocab = lbl_dict.values())])
tfm(fnames[0])
输出如下
TensorCategory(5)
这样理解:每一个成员获取前一个的输出,并将处理后的结果传给下一个成员,最后一个成员的处理结果为该Transform的最后输出。
接下来将构建Datasets
构建Dataset需要考虑如下:
- 原始数据
- 对原始数据进行一系列Transform来获取输入。
- 对原始数据的一系列Transform处理来获取输出。
- 训练集和验证集的划分
如下函数指定划分依据为父目录的父目录名为’val’
splits = GrandparentSplitter(valid_name='val')(fnames)
对输入的处理为PILImage.create ,即将输入的文件名转换成图片
对输出的处理为parent_label, lbl_dict.getitem, Categorize,最后获取的就是标签。
dsets = Datasets(fnames, [[PILImage.create], [parent_label, lbl_dict.__getitem__, Categorize]], splits=splits)
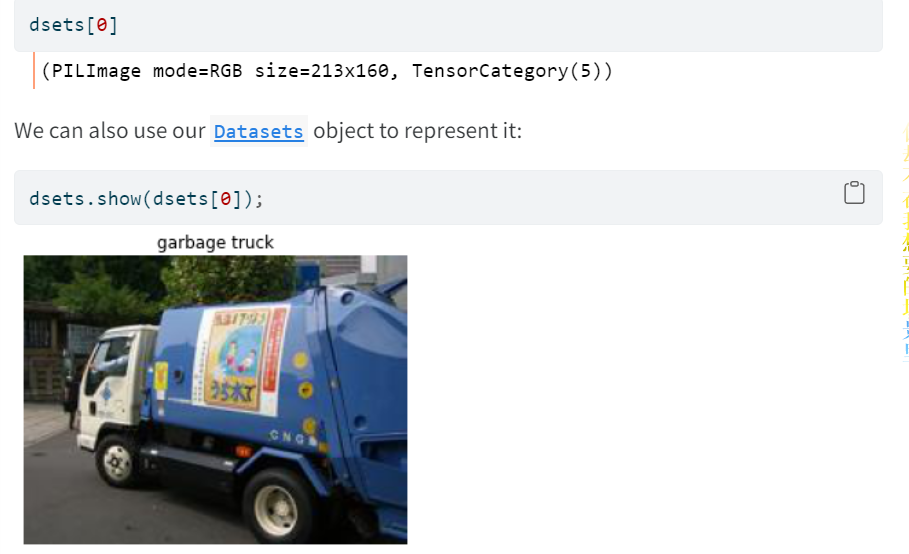
我们可以通过show来查看数据集每个成员(item)
进一步 的处理(构造Dataloader)
我们训练时需要的是
对item(单一样本)进行进一步的处理
- 将他们转换成tensor
- resize一下图片
item_tfms = [ToTensor, RandomResizedCrop(128, min_scale=0.35)]
对batch( 一批样本,我们实际训练时用到的)进行进一步处理
- 将int tensor类型和转换成float tensor类型
- 使用 ImageNet 的统计数据进行标准化。
batch_tfms = [IntToFloatTensor, Normalize.from_stats(*imagenet_stats)]
当然,我们也可以在处理items时使用这个Transform,不过在batch时处理效率更高。
最后,我们可以通过构造好的Dataset的dataloaders方法来构造Dataloader ,我们向其传入after_item ,after_batch 来传入我们自定义的Transform。
dls = dsets.dataloaders(after_item=item_tfms, after_batch=batch_tfms, bs=64, num_workers=8)
1.4 使用我们定义好的Dataloader进行训练
我们首先使用vision_learner来快速开始训练,然后我们将学习如何构建一个Learner ,为此我们将学习如何自定义以下内容:
- 如何通过fastai编写一个损失函数。
- 如何编写优化函数以及如何调用Pytorch的优化函数。
- 如何编写一个基本的回调函数。
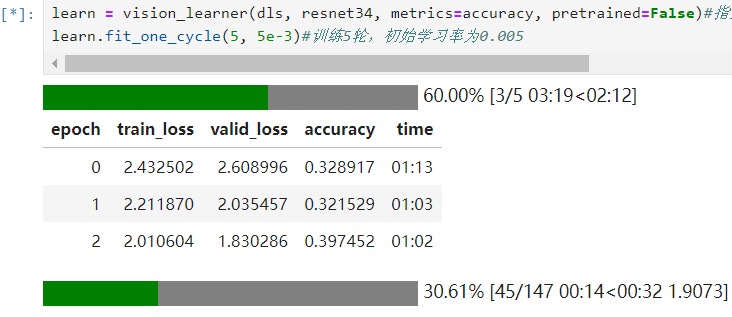
通过vision_learner 快速开始训练
learn = vision_learner(dls, resnet34, metrics=accuracy, pretrained=False)#指定模型、是否预训练、衡量指标
learn.fit_one_cycle(5, 5e-3)#训练5轮,初始学习率为0.005
训练完成后我们可以调用predict和show_results方法来进行预测
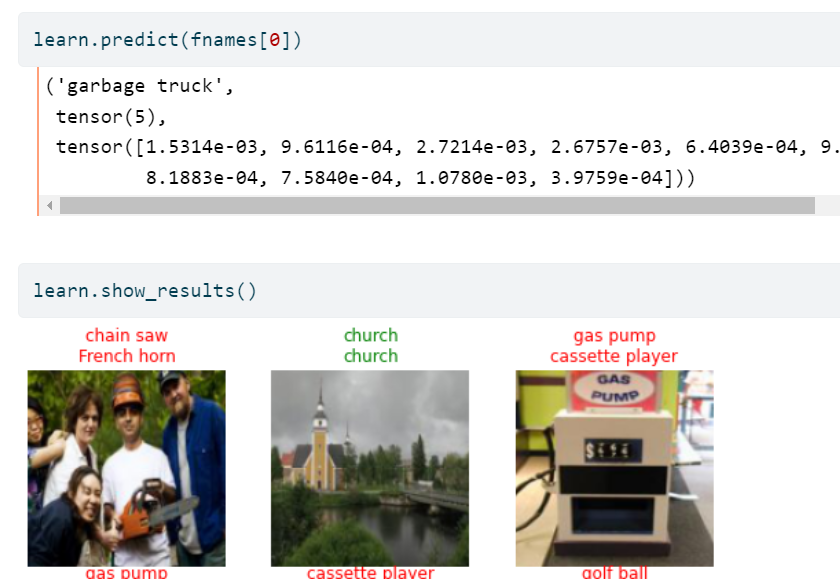
我们可以自定义一个Learner来指定不同的网络
learn = Learner(dls, xresnet34(n_out=10), metrics=accuracy)
修改损失函数
传入Learner的损失函数的参数为标签(target)和模型输出(output) ,函数的返回值为损失(loss),使用常规的Pytorch代码来实现损失函数在训练阶段不会发生什么奇怪的错误。
不过当使用Learner.get_preds, Learner.predict 或者Learner.show_results.时可能会产生奇怪的bug.
如果你想让 Learner.get_preds 方法在 with_loss=True 参数下工作(比如当你运行 ClassificationInterpretation.plot_top_losses 时也会用到),你的损失函数需要有一个可以设置为 “none” 的 reduction 属性(或参数)。设置为 “none” 后,损失函数不返回单一数值(如平均或总和),而是返回与target同样size的一系列值。
对于 Learner.predict 或 Learner.show_results,它们内部依赖于你的损失函数应该具备的两个方法:
- 一个
activation函数(激活)。如果你有一个将激活和损失函数结合在一起的损失(如nn.CrossEntropyLoss) - 一个
decodes函数,用于将你的预测转换为与你的目标相同的格式:例如,在nn.CrossEntropyLoss的情况下,decodes函数应该取argmax。
以下是一个例子
class LabelSmoothingCE(Module):
def __init__(self, eps=0.1, reduction='mean'): self.eps,self.reduction = eps,reduction
def forward(self, output, target):
c = output.size()[-1]
log_preds = F.log_softmax(output, dim=-1)
if self.reduction=='sum': loss = -log_preds.sum()
else:
loss = -log_preds.sum(dim=-1) #We divide by that size at the return line so sum and not mean
if self.reduction=='mean': loss = loss.mean()
return loss*self.eps/c + (1-self.eps) * F.nll_loss(log_preds, target.long(), reduction=self.reduction)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)
我们可以通过loss_func 来指定自定义的损失函数。
learn = Learner(dls, xresnet34(n_out=10), loss_func=LabelSmoothingCE(), metrics=accuracy)
修改优化器
fastai 使用其自己构建的优化器(Optimizer)类,该类通过各种回调来重构通用功能,并为起相同作用的优化器超参数提供唯一命名(如 SGD 中的动量(momentum),它与 RMSProp 中的 alpha 和 Adam 中的 beta0 相同),这使得更容易对它们进行调度(如在 Learner.fit_one_cycle 中)。
它实现了 PyTorch 支持的所有优化器(甚至更多),因此你应该不需要使用来自 PyTorch 的优化器。可以查看优化器模块(optimizer module)以了解所有本地可用的优化器。
然而,在某些情况下,你可能需要使用不在 fastai 中的优化器(例如,如果它是一个仅在 PyTorch 中实现的新优化器)。在学习如何将代码移植到fastai的内部优化器之前(可以查看优化器模块以了解更多信息),你可以使用 OptimWrapper 类来封装你的 PyTorch 优化器并用它进行训练。
pytorch_adamw = partial(OptimWrapper, opt=torch.optim.AdamW)
learn = Learner(dls, xresnet18(), lr=1e-2, metrics=accuracy,
loss_func=LabelSmoothingCrossEntropy(),
opt_func=partial(pytorch_adamw, weight_decay=0.01, eps=1e-3))
mixup技术
Mixup 是一种数据增强(Data Augmentation)技术,用于提高神经网络模型的泛化能力。这个方法是在训练过程中用于生成新的训练样本的。具体来说,Mixup 通过线性地混合两个随机选择的训练样本(以及它们对应的标签)来生成一个新的样本。
假设我们有两个样本(x1,y1) 和(x2,y2),以及一个从 Beta 分布中采样的混合系数 λ。Mixup 会创建一个新的样本 (x′,y′),其中:
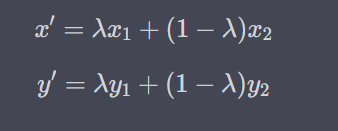
这样,模型在训练时不仅仅看到原始的样本,还会看到这些混合生成的新样本,从而有可能提高其对未见过数据的泛化性能。
Mixup 主要用于图像分类任务,但也可以应用于其他类型的数据和任务。这种方法被证明能够提高模型在多种任务和数据集上的性能。
修改 循环
一个好的训练循环应该有如下结构
for xb,yb in dl:
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
其中model 、loss_func 、opt都是FastAI的Learner的属性。
为了轻松地在训练循环中添加新的行为(如分布式训练等),而不需要自己重写整个循环,你可以通过编写回调(callback)来自定义训练循环。
关于回调函数基本的功能如下:
- 回调可以读取
Learner的每一部分,因此可以了解训练循环中发生的一切。 - 回调可以改变
Learner的任何部分,从而有能力改变训练循环的行为。 - 回调甚至可以触发特殊的异常,这将允许设置断点(跳过某一步、验证阶段、一个epoch 或者完全取消训练)
接下来我们将通过编写回调函数来实现这个功能。
class Mixup(Callback):
run_valid = False
def __init__(self, alpha=0.4): self.distrib = Beta(tensor(alpha), tensor(alpha))
def before_batch(self):
self.t = self.distrib.sample((self.y.size(0),)).squeeze().to(self.x.device)
shuffle = torch.randperm(self.y.size(0)).to(self.x.device)
x1,self.y1 = self.x[shuffle],self.y[shuffle]
self.learn.xb = (x1 * (1-self.t[:,None,None,None]) + self.x * self.t[:,None,None,None],)
def after_loss(self):
with NoneReduce(self.loss_func) as lf:
loss = lf(self.pred,self.y1) * (1-self.t) + lf(self.pred,self.y) * self.t
self.learn.loss = loss.mean()
通过指定cbs来调用它
learn = Learner(dls, xresnet18(), lr=1e-2, metrics=accuracy,
loss_func=LabelSmoothingCrossEntropy(), cbs=Mixup(),
opt_func=partial(pytorch_adamw, weight_decay=0.01, eps=1e-3))
参考文章
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com