Datasets、Pipeline、TfmdLists、Transform
文档地址:https://docs.fast.ai/tutorial.pets.html
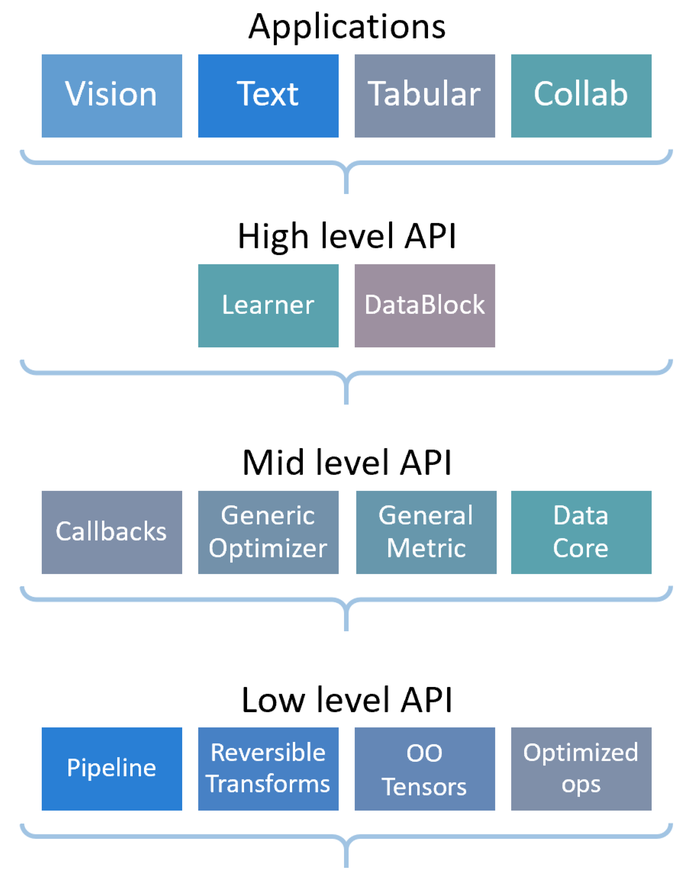
总览
首先我们将学习
- 用
Transform来处理数据 - 用
PipeLine来组合Transform
然后我们将学习
- 通过
TfmdLists将一个组合了Transform的PipeLine应用到数据集中 - 通过
Datasets将几个组合了Transform的PipeLine并行的应用到数据集中
(翻译可能不准确,原文如下)
TfmdListsto apply onePipelineofTransformon a collection of itemsDatasetsto apply severalPipelineofTransformon a collection of items in parallel and produce tuples
我们的最终目的是
通过一系列的Transform,将原始数据集(items)最终组织成一个Dataloader进行训练。
1. 数据处理
数据清洗和预处理是机器学习流程中最为时间密集的环节之一,这也是 fastai 框架致力于在这方面为您提供尽可能多的支持的原因。从本质上讲,为模型准备数据可以被规范化为一系列针对原始数据项的转换操作。举一个经典的图像分类问题为例,流程起始于图像文件的文件名。首先,需要打开这些对应的图像文件,对其进行尺寸调整,再将其转换为张量格式,可能还需要进行数据增强操作,最后才能对其进行批量处理以供模型训练。而这仅仅是模型输入的准备步骤,对于输出目标(即标签),还需要从文件名中解析并将其转化为整数形式。
这个过程需要是相对可逆的,因为我们经常需要检查我们的数据,以二次确认我们提供给模型的输入是否合理。这就是为什么 fastai 通过“转换(Transforms)”来表示所有这些操作,而这些转换有时可以通过一个 decode 方法来撤销。这种设计允许数据科学家或机器学习工程师在模型训练过程中更容易地进行数据验证和审查。
1.1 Transform
接下来我们通过MINST_TINY数据集(只包含3和7两个类别) 进行讲解。
我们首先通过一个文件名来开始,然后看看如何将其一步步处理成一个可以被模型使用的 带有标签的数据。
from fastai.vision.all import *
source = untar_data(URLs.MNIST_TINY)/'train'
items = get_image_files(source)
fn = items[0];
fn #fn是一个Path类型的变量
我们获取items就是某个文件夹下的所有文件(Path类型):
Path('C:/Users/qwrdxer/.fastai/data/mnist_tiny/train/3/7.png')
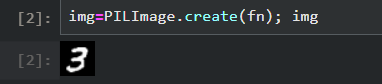
调用PIL库我们可以通过Path查看这个图片
img=PILImage.create(fn); img
然后我们可以将其转换成一个 C*H*W的tensor( C 是通道数量,HW分别为高和宽 )
tconv = ToTensor()
img = tconv(img)
img.shape,type(img)

转换成tensor后, 我们可以创建它的标签了,这个数据集的图片的父目录就是它的标签( /3/7.png ,3为它的标签),
lbl = parent_label(fn) # lbl的值为 '3'
#然后将其转换成一个整形的标签
tcat = Categorize(vocab=['3','7']) #c
lbl = tcat(lbl) # lbl的值为TensorCategory(0)
#我们也可以通过decode方法将TensorCategory(0) 重新转换回'3'
lbld = tcat.decode(lbl) #lbld的值为 '3'
1.2 Pipeline
上文中我们首先使用 PILImage.create将Path 转换成图片 ,然后使用 tconv 将其转换成tensor .
我们可以将这两个步骤通过PipeLine进行合并
pipe = Pipeline([PILImage.create,tconv])
img = pipe(fn)
img.shape
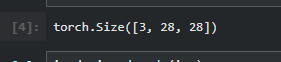
Pipline可以将图片decode并展示出来
pipe.show(img, figsize=(1,1), cmap='Greys');

转换(Transforms)会确保它们接收的元素的类型得以保留。例如,PILImage.create 返回一个 PILImage 对象,该对象知道如何show自己。tconv 将其转换为 TensorImage,该类型同样也知道如何show自己。
2.仅使用Transform加载数据集
总之,Transform是对原始数据处理的方法 ,我们接下来将尝试构建一个Transform,它能对原始的数据集进行处理(encode),也能将处理好的数据(tensor)展示出来(decode)
2.0在使用Transform前 的处理
首先我们先获取items(未处理的数据集)
source = untar_data(URLs.PETS)/"images"
items = get_image_files(source)
第一步处理是将其大小裁剪成一致的形式
def resized_image(fn:Path, sz=128):
x = Image.open(fn).convert('RGB').resize((sz,sz))
# Convert image to tensor for modeling
return tensor(array(x)).permute(2,0,1).float()/255.
在定义我们的Transform之前,我们需要一个类来知道如何展示自己(如果需要调用.show方法的话)
class TitledImage(fastuple):
def show(self, ctx=None, **kwargs): show_titled_image(self, ctx=ctx, **kwargs)
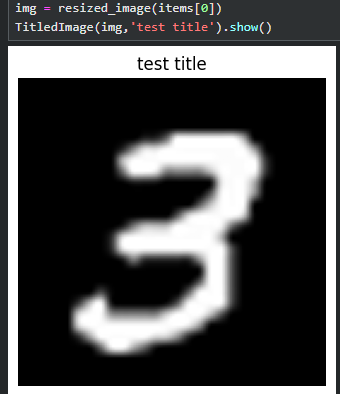
然后使用
img = resized_image(items[0])
TitledImage(img,'test title').show()
2.1使用Transform来处理图片
首先我们先加载数据集
source = untar_data(URLs.PETS)/"images"
items = get_image_files(source)
items的示例成员如下:
Path('C:/Users/qwrdxer/.fastai/data/oxford-iiit-pet/images/Abyssinian_1.jpg')
文件名即为类别 ,其中首字母大写的为猫,首字母小写的为狗,如这里的示例,A为大写,代表这是一只猫, Abyssinian是它的品种。

我们定义Transform如下:
class PetTfm(Transform):
def __init__(self, vocab, o2i, lblr): self.vocab,self.o2i,self.lblr = vocab,o2i,lblr
def encodes(self, o): return [resized_image(o), self.o2i[self.lblr(o)]]
def decodes(self, x): return TitledImage(x[0],self.vocab[x[1]])
encodes方法输入的是一张图片,输出是[resize后的图片 , 对应的标签]
decodes方法输入的是[resize后的图片 , 对应的标签], 输出是对 TitledImage的调用,这将展示这张图片。
vocab 存储了数据集所有的标签
o2i将标签转成索引
为了使用这个Transform, 我们需要写一个获取标签函数,我们获取标签的思路就是使用正则从文件名中提取
labeller = using_attr(RegexLabeller(pat = r'^(.*)_\d+.jpg$'), 'name')
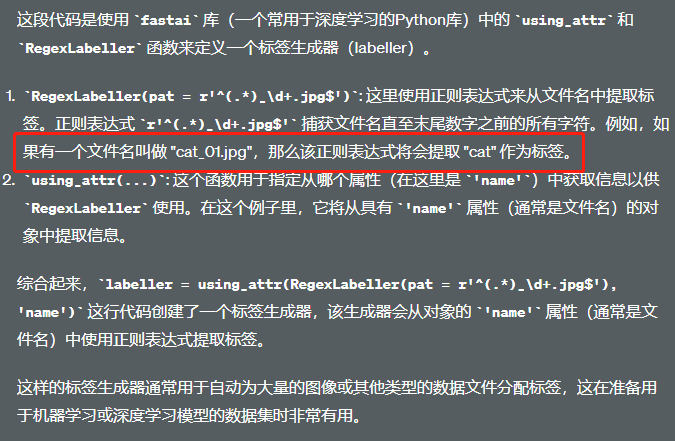
我们使用labeller来遍历数据集获得所有可能的标签
vals = list(map(labeller, items))
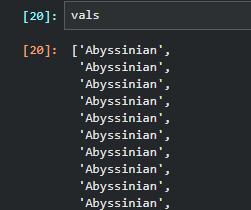
接下来是构造vocab 和一个从索引到标签的映射
vocab,o2i = uniqueify(vals, sort=True, bidir=True)
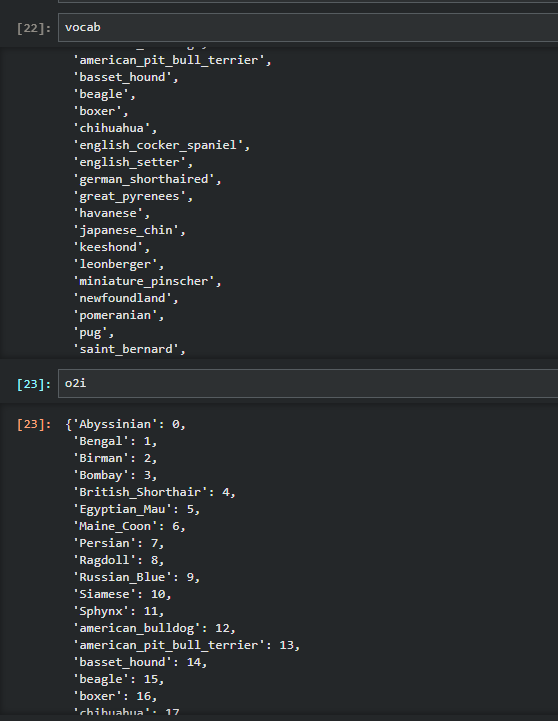
现在我们可以创建Transform实例了
pets = PetTfm(vocab,o2i,labeller)
encode测试
x,y = pets(items[0])
x.shape,y

decode测试
dec = pets.decode([x,y])
dec.show()

2.2使用setups来设置内部函数
上文对标签的处理是在Transform外面单独处理,随后通过 init方法将其传入Transform中,这种方式的封装性并不好,接下来我们将使用setups方法来将处理的过程封装到Transform中。
其实很简单,只要将用到的代码写入setups方法中即可。
class PetTfm(ItemTransform):
def setups(self, items):
self.labeller = using_attr(RegexLabeller(pat = r'^(.*)_\d+.jpg$'), 'name')
vals = map(self.labeller, items)
self.vocab,self.o2i = uniqueify(vals, sort=True, bidir=True)
def encodes(self, o): return (resized_image(o), self.o2i[self.labeller(o)])
def decodes(self, x): return TitledImage(x[0],self.vocab[x[1]])
pets = PetTfm()
pets.setup(items)# 调用setup来处理
x,y = pets(items[0])
x.shape, y
2.3通过PipLine将Transform结合起来
上文中我们定义了PetTfm,我们可以将其和ToTensor、Resize、FlipItem通过Pipeline结合起来
tfms = Pipeline([PetTfm(), Resize(224), FlipItem(p=1), ToTensor()])
对PipLine的实例调用setup会按顺序调用所有Transform的setup。
tfms.setup(items)
我们可以看看vocab来检验是否setup被正确的调用了
tfms.vocab
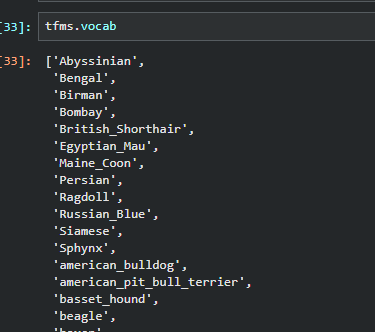
然后我们就可以使用我们的PipLine了
Then we can call our pipeline:
x,y = tfms(items[0])
x.shape,y
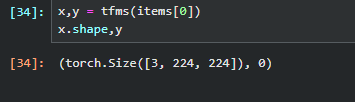
tfms.show(tfms(items[0]))
pipline的.show方法会尝试调用每个Transform的decode方法直到某个Transform知道如何展示自己。
2.4 PipLine的顺序
在PIPLine中的Transform会按照其自己的order(默认值为0)属性进行排序
我们可以通过直接调用PIPLine实例的方式来查看顺序
tfms

我们也可以查看Transform的order属性
FlipItem.order,Resize.order,ToTensor.order,PetTfm.order

我们可以将PetTfm的order值设置为一个负数确保它一定是第一个被使用的。
class PetTfm(ItemTransform):
order = -5
def setups(self, items):
self.labeller = using_attr(RegexLabeller(pat = r'^(.*)_\d+.jpg$'), 'name')
vals = map(self.labeller, items)
self.vocab,self.o2i = uniqueify(vals, sort=True, bidir=True)
def encodes(self, o): return (PILImage.create(o), self.o2i[self.labeller(o)])
def decodes(self, x): return TitledImage(x[0],self.vocab[x[1]])
这样我们就可以在构造PIPLine时随意指定PetTfm的位置,PIPLine会根据order的值自动排序的。
tfms = Pipeline([Resize(224), PetTfm(), FlipItem(p=1), ToTensor()])
tfms

3.TfmdLists和Datasets
接下来是对PIPLine的进一步使用
TfmdLists和Datasets的主要区别是PIPLine的数量。
TfmdLists这个类接收一个PIPLine来转换一个列表(单输出)
Datasets这个了可以同时接收多个PIPLine, 并且将他们并行应用于原始数据(多输出)
**我们的最终目的是:通过TfmdLists或Datasets 来获取一个Dataloader **
3.1 TfmdLists
创建一个TfmdLists只需要一个数据源(items)和一系列Transform组成的PIPLine
tls = TfmdLists(items, [Resize(224), PetTfm(), FlipItem(p=0.5), ToTensor()])
x,y = tls[0]#数据获取
x.shape,y #输出为(torch.Size([3, 224, 224]), 14)
值得注意的是我们并不在需要向PetTfm传入items了,因为在TfmdLists初始化时会自动将数据源(items)传入PIPLine中
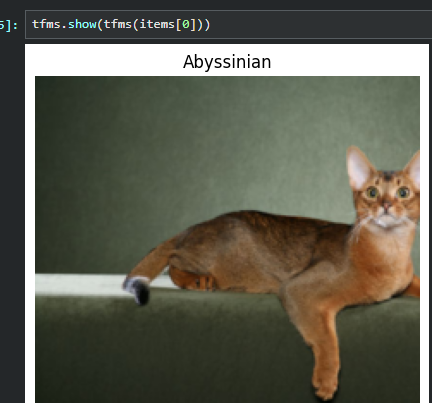
可以让我们的TfmdLists实例展示我们获取到的数据 (tls.show()调用了PetTfm的decodes方法)
tls.show((x,y))
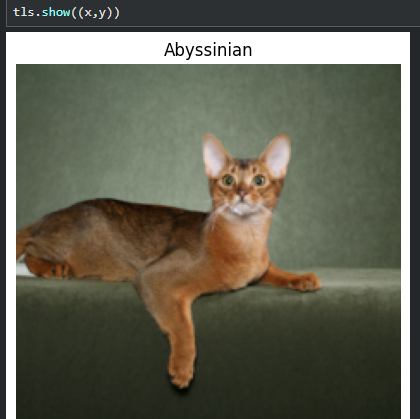
也可以调用show_at来展示调用
show_at(tls, 0)
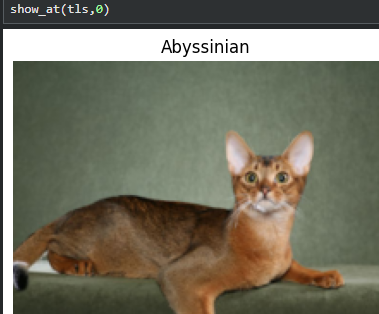
3.2训练集和验证集的生成
TfmdLists 这个单词是个带有 ‘s’的复数,因为它可以包含几个经过Transform处理后的List:训练集和验证集。
为了对转换后的数据进行划分,我们只需要在初始化时传入一个splits。
我们先单独看看splits是怎样工作的
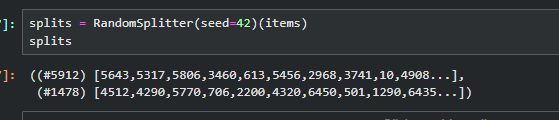
splits = RandomSplitter(seed=42)(items)#通过设置seed可以确保每次生成的随机数都相同
splits
现在,将这个splits传入TfmdLists中
tls = TfmdLists(items, [Resize(224), PetTfm(), FlipItem(p=0.5), ToTensor()], splits=splits)
show_at(tls.train, 0)
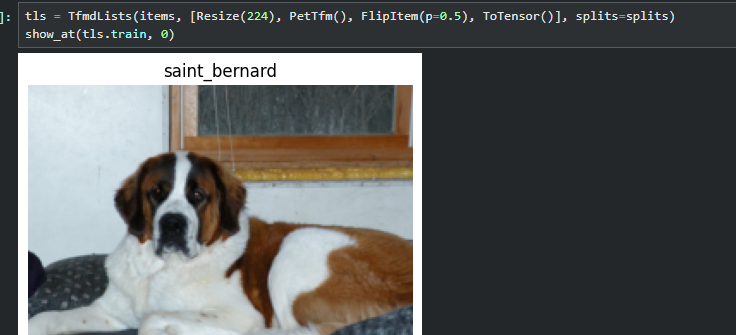
此时数据集已经按照splits的规定分成了train和vaid 两份。
3.2从TfmdLists获得Dataloaders
只拥有数据集并不能够直接进行训练,我们正常训练的方式是获取一个Dataloader,每次从其中获得一批数据用于训练。
通过TfmdLists来获取Dataloader
dls = tls.dataloaders(bs=64)
然后我们可以调用show_batch来查看数据

同时也可以进一步增加一些图片增强的Transform, 要记得在图片增强前加上IntToFloatTensor(因为图片增强需要float类型的tensor)
dls = tls.dataloaders(bs=64, after_batch=[IntToFloatTensor(), *aug_transforms()])
dls.show_batch()
3.3小总结
到此为止,我们知道了:
- 如何构建一个完善的Transform(包含encode和decode)
- 如何通过PIPLine将 多个Transform结合起来,以及他们的优先级
- 将原始数据源和一个PIPLine整合成一个TfmdLists
- 如何对TfmdLists进一步处理(获取训练集验证集)、如何从TfmdLists获取Dataloader
3.4Datasets
Dataset对数据源应用了多个 PIPLine ,并且每个PIPLine都有一个对应的输出,其特点如下
- 懒加载(Lazily Applied):
Datasets在实际需要时才会应用这些转换。这意味着,直到你实际请求(如索引或批量加载)数据集的某个元素时,这些转换才会被执行。 - 多个Pipeline:
Datasets可以接受多个Pipeline,这允许你分别处理输入和输出(如特征和标签),或处理多模态(multimodal)数据。 - 灵活性和可复用性: 由于每一步都被封装在单独的
Pipeline或转换列表中,你可以轻松地移除、添加或更改步骤。这也使得这些步骤可以在不同的项目或不同阶段的同一项目中被复用。 - 数据块API(Data Block API)的基础:
Datasets的这种设计方式为数据块API提供了基础。在数据块API中,你可以轻松地将不同类型的输入或输出与特定的转换Pipeline相关联。这为构建复杂的数据处理流程提供了高度的灵活性。
让我们先以一个例子开始, 下面的ImageResizer例子中,我们实现了两种encode方式,他们都是对图片的大小进行改变。
class ImageResizer(Transform):
order=1
"Resize image to `size` using `resample`"
def __init__(self, size, resample=BILINEAR):
if not is_listy(size): size=(size,size)
self.size,self.resample = (size[1],size[0]),resample
def encodes(self, o:PILImage): return o.resize(size=self.size, resample=self.resample)
def encodes(self, o:PILMask): return o.resize(size=self.size, resample=NEAREST)
通过类型注释 o:PILImage和o:PILMask 对于不是这两种类型的数据这个Transform将不做任何处理。
为了创建一个Datasets, 接下来我们将创建两个PIPLine,一个用于生成图片集,一个用于生成其对应的标签
#labeller = using_attr(RegexLabeller(pat = r'^(.*)_\d+.jpg$'), 'name')
tfms = [[PILImage.create, ImageResizer(128), ToTensor(), IntToFloatTensor()],
[labeller, Categorize()]]
dsets = Datasets(items, tfms)# 创建Datasets实例
我们可以检查一下我们的代码是否正确的处理了原始数据。
t = dsets[0]
type(t[0]),type(t[1])

可以通过desets实例调用show和decode
x,y = dsets.decode(t)
x.shape,y
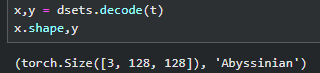
dsets.show(t);

我们也可以像TfmdLists一样传入splits
dsets = Datasets(items, tfms, splits=splits)
接下来是将Datasets转换成一个Dataloader,
一种方法是调用构建好的dsets实例的 dataloaders的方法。
dsets的成员是(x,y)类型的元组,这里值得注意的是,我们使用after_item来实现只对 图片(x) 进行处理。
tfms = [[PILImage.create], [labeller, Categorize()]]
dsets = Datasets(items, tfms, splits=splits)
dls = dsets.dataloaders(bs=64, after_item=[ImageResizer(128), ToTensor(), IntToFloatTensor()])
另一种方式是将其直接传入TfmdDL
dsets = Datasets(items, tfms)
dl = TfmdDL(dsets, bs=64, after_item=[ImageResizer(128), ToTensor(), IntToFloatTensor()])
3.5 增加一个测试集
我们的Dataloader保存有从原始数据集中获取的训练集和验证集。
假设我们还有一个跟原始数据集相同结构的测试集。
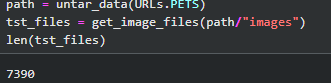
path = untar_data(URLs.PETS)
tst_files = get_image_files(path/"images")
len(tst_files)
我们可以通过训练集的Dataloader 的test_dl方法来创建一个测试集的Dataloader ,训练集的Transform会同样作用于测试集
tst_dl = dls.test_dl(tst_files)
4.最终总结
在fastAI中一共有三个大模块分别是 数据集构建 、模型训练 、预测。
本篇主要是通过fastai中较为底层的模块来演示如何将原始的数据集一步步构造成可供模型训练的Dataloader。
- Transform 是对数据处理的最基本模块,一个标准的Transform方法要实现encodes、decodes、setups方法。Transform输入是原始数据,输出是对其处理的结果。如图片分类中,我们的输入是x图片,输出就可能是(x,y)
- 我们可能对数据有多种处理, 如图片增强、resize等,将这些Transform串联起来就是一个PIPLine, PipLine会按照Transform内置的order来按顺序对数据进行处理。
- 可以对PIPLine进行调用 ,他们分别是TfmdLists和Datasets, 两者最直接的区别是TfmdLists只能接受一个PIPLine,Datasets可以接受多个PIPLine ,每个PIPLine对应一个输出。同时在Transform处理后我们可以调用split来划分训练集验证集等进一步处理
- 最后就是最终目的: 构造Dataloader,我们可以通过TfmdLists或Datasets的dataloaders方法来构建…
参考文章
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com