在FastAI中使用多GPU训练
FASTAI 默认情况下是在单个的GPU下训练的, 为了使用多GPU训练我们可以对代码做出如下修改:
在learn.fit前加上 with learn.distrib_ctx()
配置好Accelerate库的配置文件
可以在命令行中使用accelerate config
也可以在python代码中执行:
from accelerate.utils import write_basic_config write_basic_config)()
在开始前确保安装了accelerate库并创建了配置文件。
① 安装库
pip install accelerate
②配置文件生成, python执行一次下列代码即可,生成好配置文件后下列代码就不需要再次运行了
from accelerate.utils import write_basic_config
write_basic_config()
1.单GPU的代码
下面是一个简单的图片分类模型
from fastai.vision.all import *
from fastai.vision.models.xresnet import *
path = untar_data(URLs.IMAGEWOOF_320)
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
splitter=GrandparentSplitter(valid_name='val'),
get_items=get_image_files, get_y=parent_label,
item_tfms=[RandomResizedCrop(160), FlipItem(0.5)],
batch_tfms=Normalize.from_stats(*imagenet_stats)
).dataloaders(path, path=path, bs=64)
learn = Learner(dls, xresnet50(n_out=10), metrics=[accuracy,top_k_accuracy]).to_fp16()
learn.fit_flat_cos(2, 1e-3, cbs=MixUp(0.1))
可以看到只有一个GPU在训练,每轮训练时间大概用了30秒
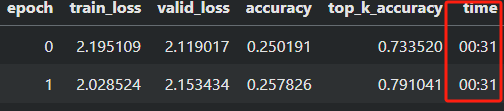
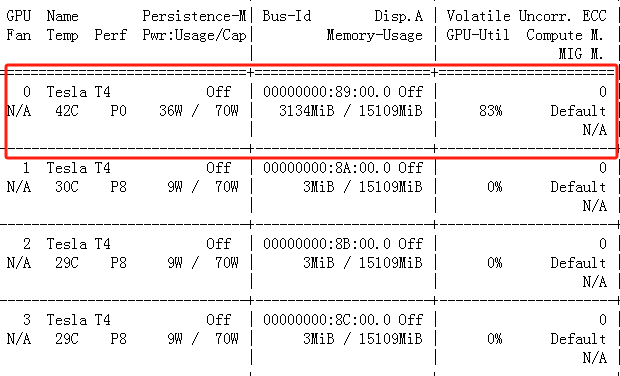
2.修改为多GPU代码
from fastai.vision.all import *
from fastai.distributed import *
from fastai.vision.models.xresnet import *
path = rank0_first(untar_data, URLs.IMAGEWOOF_320)
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
splitter=GrandparentSplitter(valid_name='val'),
get_items=get_image_files, get_y=parent_label,
item_tfms=[RandomResizedCrop(160), FlipItem(0.5)],
batch_tfms=Normalize.from_stats(*imagenet_stats)
).dataloaders(path, path=path, bs=64)
learn = Learner(dls, xresnet50(n_out=10), metrics=[accuracy,top_k_accuracy]).to_fp16()
with learn.distrib_ctx(): learn.fit_flat_cos(2, 1e-3, cbs=MixUp(0.1))
主要修改了如下代码
① from fastai.distributed import *
这是FASTAI内置的一个分布式训练库
②path = rank0_first(untar_data, URLs.IMAGEWOOF_320)
在分布式训练中,通常有多个进程同时运行。如果每个进程都试图执行某些操作(例如下载数据集),这可能会导致不必要的复杂性和资源浪费。rank0_first 装饰器确保只有一个进程(通常是主进程,即 rank 0)实际执行该操作,而其他进程会等待这个操作完成。
③with learn.distrib_ctx(): learn.fit_flat_cos(2, 1e-3, cbs=MixUp(0.1))
with learn.distrib_ctx():会激活分布式上下文,在这个上下文里面执行的所有操作都会适应多卡或多节点环境。
修改后的代码如下,我们将其保存为train.py
from fastai.vision.all import *
from fastai.distributed import *
from fastai.vision.models.xresnet import *
path = rank0_first(untar_data, URLs.IMAGEWOOF_320)
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
splitter=GrandparentSplitter(valid_name='val'),
get_items=get_image_files, get_y=parent_label,
item_tfms=[RandomResizedCrop(160), FlipItem(0.5)],
batch_tfms=Normalize.from_stats(*imagenet_stats)
).dataloaders(path, path=path, bs=64)
learn = Learner(dls, xresnet50(n_out=10), metrics=[accuracy,top_k_accuracy]).to_fp16()
with learn.distrib_ctx(): learn.fit_flat_cos(2, 1e-3, cbs=MixUp(0.1))
命令行中执行
accelerate launch train.py
可以看到每个GPU都参与了模型 训练,且训练时间也降低到了16秒( 由于数据通信、模型大小、数据集规模的影响不可能完全缩短到原来的1/8)

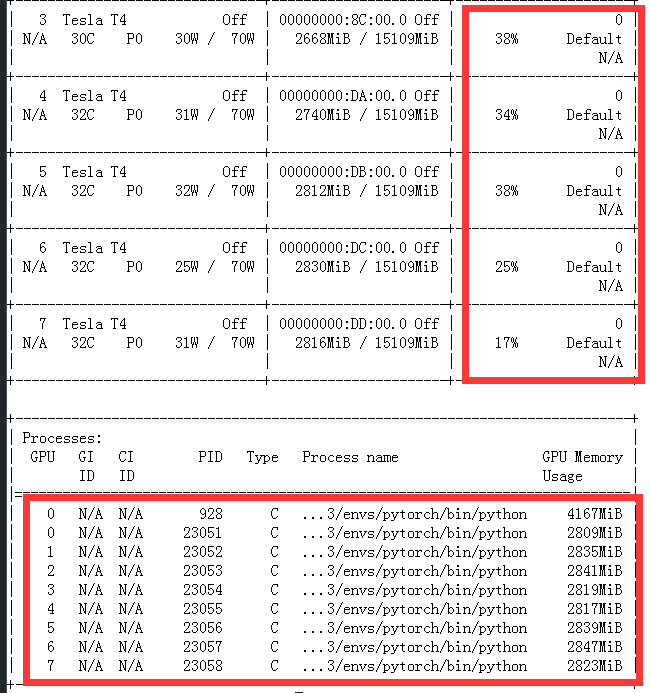
3.Accelerate介绍
Hugging Face 的 accelerate 库是一个轻量级的 Python 库,用于简化深度学习模型在 CPU、单个 GPU、多个 GPU 以及 TPU 上的训练和推理。这个库设计得非常简单,使得它能快速地与现有的 PyTorch 或 TensorFlow 代码集成。
accelerate 库的主要特点包括:
①简单性
该库的 API 设计得非常直观和易用,以便于快速上手。你可以在几行代码内实现模型和数据加载器的加速。
②灵活性
虽然简单,但 accelerate 依然提供了许多高级选项,以便您自定义硬件加速设置。
③跨平台支持
accelerate 支持多种硬件平台,包括 CPU、单个或多个 GPU,以及 Google 的 TPU。
④集成
这个库可以很容易地与其他 Hugging Face 生态系统的组件(例如 Transformers)集成,但也可以与非 Hugging Face 的项目一同使用。
⑤使用示例
下面是一个使用 accelerate 对 PyTorch 代码进行加速的简单示例:
from accelerate import Accelerator
import torch
import torch.nn as nn
# 初始化 accelerator
accelerator = Accelerator()
# 准备数据和模型
model = nn.Linear(10, 10)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
data = torch.rand(5, 10)
# 使用 accelerator 准备模型和数据
model, optimizer, data = accelerator.prepare(model, optimizer, data)
# 前向和后向传播
output = model(data)
loss = torch.mean(output)
loss.backward()
optimizer.step()
在这个例子中,Accelerator 对象负责管理硬件加速。通过调用 accelerator.prepare() 方法,你可以将模型、优化器和数据发送到加速器(可能是 GPU 或 TPU)上。
这只是一个非常基础的例子,accelerate 还有更多高级功能和选项,允许你进行更细粒度的控制。
总的来说,accelerate 提供了一个简单但功能强大的方式,以利用多种硬件加速选项,无需进行大量代码更改。这使得它成为在多种硬件配置上进行深度学习训练和推理的理想选择。
参考文章
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com