待解决的难点
操作https://blog.csdn.net/cfy_banq/article/details/131863274
option
枚举
困惑点
1.rust中有所有权的概念,我调用prinln!来输出变量会将变量所有权转给println!吗?
在 Rust 中,调用 println! 宏并不会转移变量的所有权。这是因为 println! 通常接受一个变量的引用或者是实现了 Copy trait 的类型,而不是变量本身。
在 Rust 的标准库中,很多类型都实现了 Copy trait,包括所有整数类型、浮点数类型和字符类型等。当一个类型实现了 Copy trait,这意味着在赋值或者函数调用过程中,它的数据会被复制而不是移动,因此其所有权不会被转移。
对于没有实现 Copy trait 的复杂类型(比如 String 或自定义的结构体和枚举),println! 通常会使用一个不可变引用 &T,这样也不会转移所有权。
下面是一些例子:
rustCopy codelet x = 42; // i32 类型,实现了 Copy trait
println!("x is: {}", x); // 打印 x 的值
println!("x is: {}", x); // 因为 i32 是 Copy 的,这里依然可以使用 x
let s = String::from("hello");
println!("s is: {}", s); // 使用不可变引用打印 s 的值
println!("s is: {}", s); // s 的所有权没有被转移,依然可以使用
总之,使用 println! 宏并不会转移变量的所有权,所以你可以放心地在后续代码中使用这些变量。
2. 为什么用的是=coin而不是==coin
if let Coin::Quarter(state) = coin {
println!("State quarter from {:?}!", state);
} else {
count += 1;
}
在 Rust 中,if let 语句用于模式匹配。在这里,= 并不是一个比较运算符(这会是 ==);相反,它用于解构和匹配 coin 的值。如果 coin 是 Coin::Quarter(state) 类型,state 将包含 Quarter 的值,并执行大括号内的代码。
这里是一个简单的解释:
==是一个比较运算符,用于检查两个值是否相等。=是一个赋值运算符,在模式匹配中用于解构值。
在 if let 表达式中,= 符号的目的是尝试将右侧的 coin 解构为左侧的模式 Coin::Quarter(state)。如果这个尝试成功,那么 state 变量将包含 Quarter 的值,然后执行 if 分支内的代码。
下面是一个完整的例子,解释了这个过程:
rustCopy codeenum UsState {
Alabama,
Alaska,
// etc
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Quarter(UsState::Alaska);
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {:?}!", state);
} else {
count += 1;
}
println!("Count: {}", count);
}
运行这个程序会输出:
vbnetCopy codeState quarter from Alaska!
Count: 0
这里 Coin::Quarter(state) = coin 成功匹配,所以 state 被赋值为 UsState::Alaska,并执行了 println!("State quarter from {:?}!", state);。count 没有增加,因为 else 分支没有执行。
3.在rust中,let v = vec![1, 2, 3, 4, 5]; let third: i32 = v[2]; 这是否意味着v[2]元素的所有权已经给了third
在Rust中,基本类型(如i32、f64、bool等)是实现了Copy trait的,这意味着当你做类似let third: i32 = v[2];这样的操作时,实际上是把v[2]的值复制到了third变量中,而不是转移所有权。
对于实现了Copy trait的类型,赋值操作会复制值,而不会转移所有权。因此,在这种情况下,v仍然拥有其所有元素的所有权,third则拥有一个新的、与v[2]相等的值。
下面是代码:
rustCopy codelet v = vec![1, 2, 3, 4, 5];
let third: i32 = v[2]; // third 现在是 3,而 v[2] 的值并没有改变。
这里,v的结构和所有权没有受到影响。你之后仍然可以正常使用v和它的元素,包括v[2]。
需要注意的是,这种行为是基本类型特有的。如果v是一个存储了更复杂类型(比如自定义结构体或枚举)的向量,并且这些类型没有实现Copy trait,那么尝试进行类似的赋值操作会导致编译器错误,除非你显式地使用.clone()方法或其他复制手段。
多线程为什么字符串切片生命周期短暂
Rust 中的字符串切片(&str)是对某个字符串数据的不可变引用,它由一个指针和一个长度组成。这个切片实际上没有拥有它所引用的数据,它只是“借用”了这份数据。因此,切片的生命周期总是受到其所引用的原始数据(即字符串字面量、String 对象等)的生命周期的限制。
考虑下面的代码:
rustCopy codelet mut target_ip_input = String::new();
io::stdin().read_line(&mut target_ip_input).unwrap();
let target_ip = target_ip_input.trim_end();
在这里,target_ip 是一个字符串切片,它是 target_ip_input 的一个部分。它不拥有数据,只是一个指向 target_ip_input 中某个部分的引用。因此,target_ip 的生命周期是受 target_ip_input 的生命周期限制的。
当你尝试在一个线程中使用 target_ip 时,Rust 的生命周期检查器会发现一个问题。线程可能会在 main() 函数结束后继续运行,而 main() 函数结束时,target_ip_input(以及由其产生的 target_ip 切片)都将被销毁。这意味着线程可能会尝试访问一个已经被销毁的字符串,这是不安全的。
解决这个问题的一种方法是创建一个新的 String 对象(它拥有其数据)并传递这个对象(或其克隆)给线程。因为这个新的 String 对象拥有其数据,它可以安全地传递给线程,不受原始 String 对象(在这种情况下是 target_ip_input)生命周期的限制。
这就是为什么将 trim_end() 的返回结果转换为 String 对象可以解决生命周期问题的原因:
rustCopy code
let target_ip = target_ip_input.trim_end().to_string();
现在 target_ip 是一个 String 对象,它拥有自己的数据。这样你就可以克隆这个 String 对象,并将克隆传递给线程,而不必担心生命周期问题了。
猜数小游戏
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
//生成一个1~100的随机数
let secret_number = rand::thread_rng().gen_range(1..101);
loop {
println!("Please input your guess.");
let mut guess = String::new();
//读取输入存入guss中
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
//通过match 来尝试将输入的guess转换成int
let guess: u32 = match guess.trim().parse() {
//.parse()调用成功会返回一个包含结果数字的Ok
Ok(num) => num,
//调用失败会返回Err
Err(_) => continue,
};
println!("You guessed: {}", guess);
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
端口扫描器
use std::io::{self, Write};
use std::net::TcpStream;
use std::thread;
fn main() {
let mut target_ip = String::new();
print!("请输入要扫描的IP地址: ");
io::stdout().flush().unwrap(); // 刷新stdout以立即显示提示
io::stdin().read_line(&mut target_ip);
// 端口范围可以按需求更改
let start_port: u16 = 20;
let end_port: u16 = 40000;
let target_ip = target_ip.trim_end().to_string();
for port in start_port..=end_port {
let target_ip = target_ip.clone();
// 用线程执行每个扫描以加速过程
thread::spawn(move || {
scan_port(&target_ip, port);
});
}
// 等待所有线程完成(简单的暂停,更好的方法是使用线程池和任务同步)
thread::sleep(std::time::Duration::from_secs(2));
}
fn scan_port(ip: &str, port: u16) {
let ip_port = format!("{}:{}", ip, port);
// println!("{}", ip_port);
if TcpStream::connect(ip_port).is_ok() {
println!("端口 {} 是打开的", port);
}
}
Rust基本概念
1.Rust 的变量默认是不可变的
let x =5;
x=4; //报错
//如果想让变量为可变变量,要加上mut关键字
let mut x =5;
x=4; //可以
2.遮蔽
你可以声明和前面变量具有相同名称的新变量。第一个变量会被第二个变量遮蔽(shadow),这意味着当我们使用变量时我们看到的会是第二个变量的值。我们可以通过使用相同的变量名并重复使用 let 关键字来遮蔽变量
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("The value of x in the inner scope is: {}", x);
}
println!("The value of x is: {}", x);
}
3.数据类型
标量类型: 整数、浮点型、布尔型、字符
let x =5;
let y:u8=5; // u8 u16 u32 u64 i8 i16 i32 i664
let z=0.4; //默认为f64
let a:f32=111;
let t = true;
let f: bool = false; // with explicit type annotation
let c = 'z'; //Rust 的字符类型大小为 4 个字节,表示的是一个 Unicode 标量值
let z = 'ℤ';
let heart_eyed_cat = '😻';
复合类型: Rust有两种基本的复合类型: 元组(tuple) 和数组(array).
元组的长度是固定的:声明后,它们就无法增长或缩小。元组中的每个位置都有一个类型,并且元组中不同值的类型不要求是相同的。
let tup: (i32, f64, u8) = (500, 6.4, 1);
let (x, y, z) = tup; //直接给xyz赋值
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0; //通过.来进行下标访问
let six_point_four = x.1;
let one = x.2;
组的每个元素必须具有相同的类型。与某些其他语言中的数组不同,Rust 中的数组具有固定长度。
let a = [1, 2, 3, 4, 5];
let months = ["January", "February", "March"];
let first = a[0];//通过下标访问数组成员
let second = a[1];
4.函数
fn main() {
let a = [1, 2, 3, 4, 5];
let result:u8=add(a[1],a[2]);
println!("{}",result);
}
fn add(x:u8,y:u8) -> u8{
return x+y;
}
通过元组可以返回多个值
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length)
}
5.控制流
条件if
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}
循环loop
fn main() {
let mut count = 0;
'counting_up: loop { //couting_up是一个标签
println!("count = {}", count);
let mut remaining = 10;
loop {
println!("remaining = {}", remaining);
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {}", count);
}
while
while index < 5 {
println!("the value is: {}", a[index]);
index += 1;
}
for in
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {}", element);
}
}
进阶-所有权
1.所有权
- Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
- 值在任一时刻有且只有一个所有者。
- 当所有者(变量)离开作用域,这个值将被丢弃。
2.作用域
{ // s 在这里无效, 它尚未声明
let s = "hello"; // 从此处起,s 开始有效
// 使用 s
} // 此作用域已结束,s 不再有效
当 s 离开作用域的时候。当变量离开作用域,Rust 为我们调用一个特殊的函数。这个函数叫做 drop,在这里 String 的作者可以放置释放内存的代码。Rust 在结尾的 } 处自动调用 drop
3.变量与数据的交互方式(一)移动
对于堆中的数据,采用深度拷贝会降低性能,rust将原变量直接无效。
let s1 = String::from("hello");
let s2 = s1;
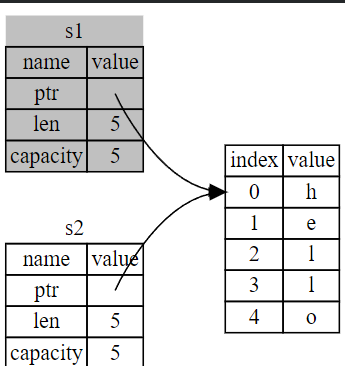
例子可以解读为 s1 被 移动 到了 s2 中,此时变量s1已经无效了。
4.变量和数据的交互方式(2): 克隆
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
5.所有权与函数
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// ... 所以到这里不再有效
let x = 5; // x 进入作用域
makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,所以在后面可继续使用 x
} // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走,
// 所以不会有特殊操作
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放
fn makes_copy(some_integer: i32) { // some_integer 进入作用域
println!("{}", some_integer);
} // 这里,some_integer 移出作用域。不会有特殊操作
函数通过返回值可以返回所有权
fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值
// 移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到
// takes_and_gives_back 中,
// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,
// 所以什么也不会发生。s1 移出作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 将返回值移动给
// 调用它的函数
let some_string = String::from("yours"); // some_string 进入作用域
some_string // 返回 some_string 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}
6.引用与借用
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
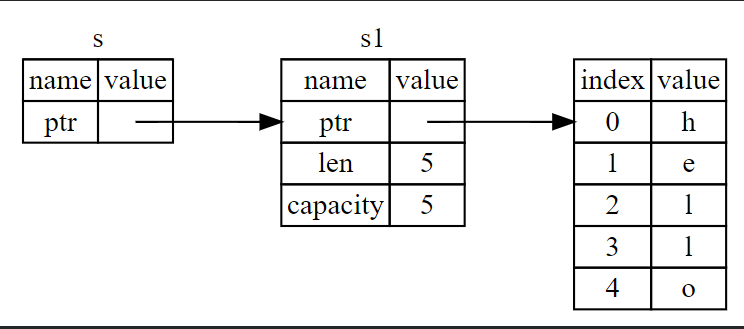
修改引用指向的值(可变引用 &mut)
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
首先,我们必须将 s 改为 mut。然后必须在调用 change 函数的地方创建一个可变引用 &mut s,并更新函数签名以接受一个可变引用 some_string: &mut String。这就非常清楚地表明,change 函数将改变它所借用的值。
不过可变引用有一个很大的限制:在同一时间,只能有一个对某一特定数据的可变引用。尝试创建两个可变引用的代码将会失败:
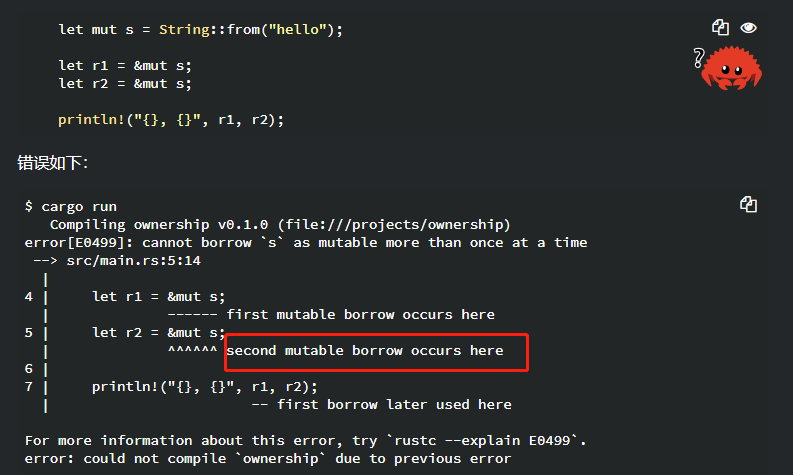
这个限制的好处是 Rust 可以在编译时就避免数据竞争。数据竞争(data race)类似于竞态条件,它由这三个行为造成:
- 两个或更多指针同时访问同一数据。
- 至少有一个指针被用来写入数据。
- 没有同步数据访问的机制。
fn main() {
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}, {}, and {}", r1, r2, r3);//这里r1 r2在声明r3后使用了,所以会导致编译不通过
}
fn main() {
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
println!("{}, {}, and", r1, r2);
let r3 = &mut s; // 没问题,因为后续的代码中,r1 r2都没有被使用。
}
7.悬垂引用
在具有指针的语言中,很容易通过释放内存时保留指向它的指针而错误地生成一个 悬垂指针(dangling pointer),所谓悬垂指针是其指向的内存可能已经被分配给其它持有者。相比之下,在 Rust 中编译器确保引用永远也不会变成悬垂状态:当你拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
让我们尝试创建一个悬垂引用,Rust 会通过一个编译时错误来避免:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle 返回一个字符串的引用
let s = String::from("hello"); // s 是一个新字符串
&s // 返回字符串 s 的引用
} // 这里 s 离开作用域并被丢弃。其内存被释放。
// 危险!
解决方法
fn no_dangle() -> String {
let s = String::from("hello");
s
}//这样就没有任何错误了。所有权被移动出去,所以没有值被释放。
8.切片slice
引用、切片都没有所有权
字符串 slice(string slice)是 String 中一部分值的引用,它看起来像这样:
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
这类似于引用整个 String 不过带有额外的 [0..5] 部分。它不是对整个 String 的引用,而是对部分 String 的引用。
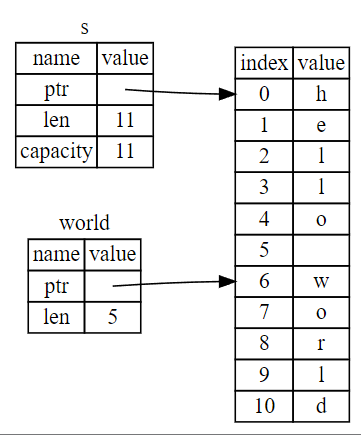
字符串切片类型为&str ,这种特殊的引用
进阶-结构体
struct,或者 structure,是一个自定义数据类型,允许你命名和包装多个相关的值,从而形成一个有意义的组合。如果你熟悉一门面向对象语言,struct 就像对象中的数据属性。
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}
注意整个实例必须是可变的;Rust 并不允许只将某个字段标记为可变。另外需要注意同其他任何表达式一样,我们可以在函数体的最后一个表达式中构造一个结构体的新实例,来隐式地返回这个实例。
fn build_user(email: String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}
1.从其他实例中创建新的结构体实例
方式1 :
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
方式2:
let user2 = User {
email: String::from("another@example.com"),
..user1 //复制user1中除了email外的值
};
在这个例子中,我们在创建 user2 后不能再使用 user1,因为 user1 的 username 字段中的 String 被移到 user2 中。如果我们给 user2 的 email 和 username 都赋予新的 String 值,从而只使用 user1 的 active 和 sign_in_count 值,那么 user1 在创建 user2 后仍然有效。active 和 sign_in_count 的类型是实现 Copy trait 的类型
2.结构体数据的声明周期
User 结构体的定义中,我们使用了自身拥有所有权的 String 类型而不是 &str 字符串 slice 类型。这是一个有意而为之的选择,因为我们想要这个结构体拥有它所有的数据,为此只要整个结构体是有效的话其数据也是有效的。
可以使结构体存储被其他对象拥有的数据的引用,不过这么做的话需要用上生命周期(lifetime)。生命周期确保结构体引用的数据有效性跟结构体本身保持一致。
3.通过派生trait增加实用的功能
如下代码会报错
#[derive(Debug)]//通过 derive 属性来使用的 trait
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}
一种使用 Debug 格式打印数值的方法是使用 dbg! 宏。dbg! 宏接收一个表达式的所有权,打印出代码中调用 dbg! 宏时所在的文件和行号,以及该表达式的结果值,并返回该值的所有权
4.方法
方法 与函数类似:它们使用 fn 关键字和名称声明,可以拥有参数和返回值,同时包含在某处调用该方法时会执行的代码。不过方法与函数是不同的,因为它们在结构体的上下文中被定义,并且它们第一个参数总是 self,它代表调用该方法的结构体实例。
文件名: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}
这里选择 &self 的理由跟在函数版本中使用 &Rectangle 是相同的:我们并不想获取所有权,只希望能够读取结构体中的数据,而不是写入。如果想要在方法中改变调用方法的实例,需要将第一个参数改为 &mut self。通过仅仅使用 self 作为第一个参数来使方法获取实例的所有权是很少见的;这种技术通常用在当方法将 self 转换成别的实例的时候,这时我们想要防止调用者在转换之后使用原始的实例。
我们可以选择将方法的名称与结构中的一个字段相同。在 main 中,当我们在 rect1.width 后面加上括号时。Rust 知道我们指的是方法 width。当我们不使用圆括号时,Rust 知道我们指的是字段 width。
带有更多参数的方法
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
关联函数
所有在 impl 块中定义的函数被称为关联函数(associated function),因为它们与 impl 后面命名的类型相关。我们可以定义不以 self 为第一参数的关联函数(因此不是方法),因为它们并不作用于一个结构体的实例。我们已经使用了一个这样的函数,String::from 函数,它是在 String 类型上定义的。
关联函数经常被用作返回一个结构体新实例的构造函数。例如我们可以提供一个关联函数,它接受一个维度参数并且同时作为宽和高,这样可以更轻松的创建一个正方形 Rectangle 而不必指定两次同样的值:
文件名: src/main.rs
impl Rectangle {
fn square(size: u32) -> Rectangle {
Rectangle {
width: size,
height: size,
}
}
}
使用结构体名和 :: 语法来调用这个关联函数:比如 let sq = Rectangle::square(3);。这个方法位于结构体的命名空间中::: 语法用于关联函数和模块创建的命名空间。第 7 章会讲到模块。
进阶-枚举和模式匹配
1.枚举类型
一个简单的例子: 任何一个 IP 地址要么是 IPv4 的要么是 IPv6 的,而且不能两者都是。IP 地址的这个特性使得枚举数据结构非常适合这个场景,因为枚举值只可能是其中一个成员.
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
注意枚举的成员位于其标识符的命名空间中,并使用两个冒号分开。这么设计的益处是现在 IpAddrKind::V4 和 IpAddrKind::V6 都是 IpAddrKind 类型的。例如,接着可以定义一个函数来获取任何 IpAddrKind:
fn route(ip_type: IpAddrKind) { }
现在可以使用任一成员来调用这个函数:
route(IpAddrKind::V4);
route(IpAddrKind::V6);
我们可以使用一种更简洁的方式来表达相同的概念,仅仅使用枚举并将数据直接放进每一个枚举成员而不是将枚举作为结构体的一部分。IpAddr 枚举的新定义表明了 V4 和 V6 成员都关联了 String 值:
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
用枚举替代结构体还有另一个优势:每个成员可以处理不同类型和数量的数据。IPv4 版本的 IP 地址总是含有四个值在 0 和 255 之间的数字部分。如果我们想要将 V4 地址存储为四个 u8 值而 V6 地址仍然表现为一个 String,这就不能使用结构体了。枚举则可以轻易地处理这个情况:
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
2. Option 枚举和其相对于空值的优势
enum Option<T> {
Some(T),
None,
}
为了拥有一个可能为空的值,你必须要显式地将其放入对应类型的 Option<T> 中。接着,当使用这个值时,必须明确地处理值为空的情况。只要一个值不是 Option<T> 类型,你就 可以 安全地认定它的值不为空。这是 Rust 的一个经过深思熟虑的设计决策,来限制空值的泛滥以增加 Rust 代码的安全性。
3.match控制流运算符
可以把 match 表达式想象成某种硬币分类器:硬币滑入有着不同大小孔洞的轨道,每一个硬币都会掉入符合它大小的孔洞。同样地,值也会通过 match 的每一个模式,并且在遇到第一个 “符合” 的模式时,值会进入相关联的代码块并在执行中被使用。
因为刚刚提到了硬币,让我们用它们来作为一个使用 match 的例子!我们可以编写一个函数来获取一个未知的硬币,并以一种类似验钞机的方式,确定它是何种硬币并返回它的美分值,如示例 6-3 中所示。
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
匹配是穷尽的!!!!!!!!!!!!!!!!
match 还有另一方面需要讨论。考虑一下 plus_one 函数的这个版本,它有一个 bug 并不能编译:
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
我们没有处理 None 的情况,所以这些代码会造成一个 bug。幸运的是,这是一个 Rust 知道如何处理的 bug。如果尝试编译这段代码,会得到这个错误:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
= help: ensure that all possible cases are being handled, possibly by adding wildcards or more match arms
= note: the matched value is of type `Option<i32>`
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` due to previous error
Rust 知道我们没有覆盖所有可能的情况甚至知道哪些模式被忘记了!Rust 中的匹配是穷举式的(exhaustive):必须穷举到最后的可能性来使代码有效。特别的在这个 Option<T> 的例子中,Rust 防止我们忘记明确的处理 None 的情况,这让我们免于假设拥有一个实际上为空的值,从而使之前提到的价值亿万的错误不可能发生。
如何处理你不关心的值呢?
让我们看一个例子,我们希望对一些特定的值采取特殊操作,而对其他的值采取默认操作。想象我们正在玩一个游戏,如果你掷出骰子的值为 3,角色不会移动,而是会得到一顶新奇的帽子。如果你掷出了 7,你的角色将失去新奇的帽子。对于其他的数值,你的角色会在棋盘上移动相应的格子。这是一个实现了上述逻辑的 match,骰子的结果是硬编码而不是一个随机值,其他的逻辑部分使用了没有函数体的函数来表示,实现它们超出了本例的范围:
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
对于前两个分支,匹配模式是字面值 3 和 7,最后一个分支则涵盖了所有其他可能的值,模式是我们命名为 other 的一个变量。other 分支的代码通过将其传递给 move_player 函数来使用这个变量。
即使我们没有列出 u8 所有可能的值,这段代码依然能够编译,因为最后一个模式将匹配所有未被特殊列出的值。这种通配模式满足了 match 必须被穷尽的要求。请注意,我们必须将通配分支放在最后,因为模式是按顺序匹配的。如果我们在通配分支后添加其他分支,Rust 将会警告我们,因为此后的分支永远不会被匹配到。
Rust 还提供了一个模式,当我们不想使用通配模式获取的值时,请使用 _ ,这是一个特殊的模式,可以匹配任意值而不绑定到该值。这告诉 Rust 我们不会使用这个值,所以 Rust 也不会警告我们存在未使用的变量。
让我们改变游戏规则,当你掷出的值不是 3 或 7 的时候,你必须再次掷出。这种情况下我们不需要使用这个值,所以我们改动代码使用 _ 来替代变量 other :
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => reroll(),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
这个例子也满足穷举性要求,因为我们在最后一个分支中明确地忽略了其他的值。我们没有忘记处理任何东西。
让我们再次改变游戏规则,如果你掷出 3 或 7 以外的值,你的回合将无事发生。我们可以使用单元值(在“元组类型”一节中提到的空元组)作为 _ 分支的代码:
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
在这里,我们明确告诉 Rust 我们不会使用与前面模式不匹配的值,并且这种情况下我们不想运行任何代码。
使用if let简洁操作
if let 语法让我们以一种不那么冗长的方式结合 if 和 let,来处理只匹配一个模式的值而忽略其他模式的情况。考虑示例 6-6 中的程序,它匹配一个 Option<u8> 值并只希望当值为 3 时执行代码:
let some_u8_value = Some(0u8);
match some_u8_value {
Some(3) => println!("three"),
_ => (),
}
示例 6-6:match 只关心当值为 Some(3) 时执行代码
我们想要对 Some(3) 匹配进行操作但是不想处理任何其他 Some<u8> 值或 None 值。为了满足 match 表达式(穷尽性)的要求,必须在处理完这唯一的成员后加上 _ => (),这样也要增加很多样板代码。
不过我们可以使用 if let 这种更短的方式编写。如下代码与示例 6-6 中的 match 行为一致:
if let Some(3) = some_u8_value {
println!("three");
}
if let 获取通过等号分隔的一个模式和一个表达式。它的工作方式与 match 相同,这里的表达式对应 match 而模式则对应第一个分支。
使用 if let 意味着编写更少代码,更少的缩进和更少的样板代码。然而,这样会失去 match 强制要求的穷尽性检查。match 和 if let 之间的选择依赖特定的环境以及增加简洁度和失去穷尽性检查的权衡取舍。
进阶-管理代码
Rust 有许多功能可以让你管理代码的组织,包括哪些内容可以被公开,哪些内容作为私有部分,以及程序每个作用域中的名字。这些功能。这有时被称为 “模块系统(the module system)”,包括:
- 包(Packages): Cargo 的一个功能,它允许你构建、测试和分享 crate。
- Crates :一个模块的树形结构,它形成了库或二进制项目。
- 模块(Modules)和 use: 允许你控制作用域和路径的私有性。
- 路径(path):一个命名例如结构体、函数或模块等项的方式
1. 包和create
crate 是一个二进制项或者库。crate root 是一个源文件,Rust 编译器以它为起始点,并构成你的 crate 的根模块,包(package)是提供一系列功能的一个或者多个 crate。一个包会包含有一个 Cargo.toml 文件,阐述如何去构建这些 crate。
包中所包含的内容由几条规则来确立。一个包中至多 只能 包含一个库 crate(library crate);包中可以包含任意多个二进制 crate(binary crate);包中至少包含一个 crate,无论是库的还是二进制的。
让我们来看看创建包的时候会发生什么。首先,我们输入命令 cargo new:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
当我们输入了这条命令,Cargo 会给我们的包创建一个 Cargo.toml 文件。查看 Cargo.toml 的内容,会发现并没有提到 src/main.rs,因为 Cargo 遵循的一个约定:src/main.rs 就是一个与包同名的二进制 crate 的 crate 根。同样的,Cargo 知道如果包目录中包含 src/lib.rs,则包带有与其同名的库 crate,且 src/lib.rs 是 crate 根。crate 根文件将由 Cargo 传递给 rustc 来实际构建库或者二进制项目。
2.模块系统
模块 让我们可以将一个 crate 中的代码进行分组,以提高可读性与重用性。模块还可以控制项的 私有性,即项是可以被外部代码使用的(public),还是作为一个内部实现的内容,不能被外部代码使用(private)。
通过如下命令创建一个lib create
cargo new --lib restaurant
文件名: src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}
通过使用模块,我们可以把相关的定义组织起来,并通过模块命名来解释为什么它们之间有相关性。使用这部分代码的开发者可以更方便的循着这种分组找到自己需要的定义,而不需要通览所有。编写这部分代码的开发者通过分组知道该把新功能放在哪里以便继续让程序保持组织性。
之前我们提到,src/main.rs 和 src/lib.rs 被称为 crate 根。如此称呼的原因是,这两个文件中任意一个的内容会构成名为 crate 的模块,且该模块位于 crate 的被称为 模块树 的模块结构的根部(”at the root of the crate’s module structure”)。
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
这个树展示了模块间是如何相互嵌套的(比如,hosting 嵌套在 front_of_house 内部)。这个树还展示了一些模块互为 兄弟 ,即它们被定义在同一模块内(hosting 和 serving 都定义在 front_of_house 内)。继续使用家族比喻,如果模块A包含在模块B的内部,我们称模块A是模块B的 孩子 且模块B是模块A的 父辈 。注意整个模块树的根位于名为 crate 的隐式模块下。
3.Rust 如何在模块树中找到一个项的位置
路径有两种形式:
- 绝对路径(absolute path)从 crate 根部开始,以 crate 名或者字面量
crate开头。 - 相对路径(relative path)从当前模块开始,以
self、super或当前模块的标识符开头。
文件名: src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// 绝对路径
crate::front_of_house::hosting::add_to_waitlist();
// 相对路径
front_of_house::hosting::add_to_waitlist();
}
第一种方式,我们在 eat_at_restaurant 中调用 add_to_waitlist 函数,使用的是绝对路径。add_to_waitlist 函数与 eat_at_restaurant 被定义在同一 crate 中,这意味着我们可以使用 crate 关键字为起始的绝对路径。
第二种方式,我们在 eat_at_restaurant 中调用 add_to_waitlist,使用的是相对路径。这个路径以 front_of_house 为起始,这个模块在模块树中,与 eat_at_restaurant 定义在同一层级。与之等价的文件系统路径就是 front_of_house/hosting/add_to_waitlist。以名称为起始,意味着该路径是相对路径。
编译这个src/lib.rs模块会报错 –> 模块的私有性
我们拥有 hosting 模块和 add_to_waitlist 函数的的正确路径,但是 Rust 不让我们使用,因为它不能访问私有片段。
模块不仅对于你组织代码很有用。他们还定义了 Rust 的 私有性边界(privacy boundary):这条界线不允许外部代码了解、调用和依赖被封装的实现细节。所以,如果你希望创建一个私有函数或结构体,你可以将其放入模块。
Rust 中默认所有项(函数、方法、结构体、枚举、模块和常量)都是私有的。父模块中的项不能使用子模块中的私有项,但是子模块中的项可以使用他们父模块中的项。
使用pub关键字暴露路径
文件名: src/lib.rs
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// 绝对路径
crate::front_of_house::hosting::add_to_waitlist();
// 相对路径
front_of_house::hosting::add_to_waitlist();
}
然而这样还是有问题, 在 mod hosting 前添加了 pub 关键字,使其变成公有的。伴随着这种变化,如果我们可以访问 front_of_house,那我们也可以访问 hosting。但是 hosting 的 内容(contents) 仍然是私有的;这表明使模块公有并不使其内容也是公有的。模块上的 pub 关键字只允许其父模块引用它。
最终版本: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// 绝对路径
crate::front_of_house::hosting::add_to_waitlist();
// 相对路径
front_of_house::hosting::add_to_waitlist();
}
使用super其实的相对路径
我们还可以使用 super 开头来构建从父模块开始的相对路径。这么做类似于文件系统中以 .. 开头的语法。我们为什么要这样做呢?
文件名: src/lib.rs
fn serve_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::serve_order();//调用
}
fn cook_order() {}
}
fix_incorrect_order` 函数在 `back_of_house` 模块中,所以我们可以使用 `super` 进入 `back_of_house` 父模块,也就是本例中的 `crate` 根。在这里,我们可以找到 `serve_order
使用pub构造公有的结构体和枚举
我们还可以使用 pub 来设计公有的结构体和枚举,不过有一些额外的细节需要注意。如果我们在一个结构体定义的前面使用了 pub ,这个结构体会变成公有的,但是这个结构体的字段仍然是私有的。
文件名: src/lib.rs
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// 在夏天点一份黑麦面包作为早餐
let mut meal = back_of_house::Breakfast::summer("Rye");
// 更改我们想要的面包
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// 如果取消下一行的注释,将会导致编译失败;我们不被允许看到或更改随餐搭配的季节水果
// meal.seasonal_fruit = String::from("blueberries");
}
如果我们将枚举设为公有,则它的所有成员都将变为公有。我们只需要在 enum 关键字前面加上 pub
src/lib.rs
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}
3.使用use关键字将名称引入域
文件名: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
在作用域中增加 use 和路径类似于在文件系统中创建软连接(符号连接,symbolic link)。通过在 crate 根增加 use crate::front_of_house::hosting,现在 hosting 在作用域中就是有效的名称了,如同 hosting 模块被定义于 crate 根一样。通过 use 引入作用域的路径也会检查私有性,同其它路径一样。
使用as关键字提供新的名称
文件名: src/lib.rs
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
}
fn function2() -> IoResult<()> {
// --snip--
}
在第二个 use 语句中,我们选择 IoResult 作为 std::io::Result 的新名称,它与从 std::fmt 引入作用域的 Result 并不冲突
使用 pub use 重导出名称
当使用 use 关键字将名称导入作用域时,在新作用域中可用的名称是私有的。如果为了让调用你编写的代码的代码能够像在自己的作用域内引用这些类型,可以结合 pub 和 use。这个技术被称为 “重导出(re-exporting)”,因为这样做将项引入作用域并同时使其可供其他代码引入自己的作用域。
文件名: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
使用外部包
文件名: Cargo.toml
[dependencies]
rand = "0.8.3"
在 Cargo.toml 中加入 rand 依赖告诉了 Cargo 要从 crates.io 下载 rand 和其依赖,并使其可在项目代码中使用。
接着,为了将 rand 定义引入项目包的作用域,我们加入一行 use 起始的包名,它以 rand 包名开头并列出了需要引入作用域的项
use rand::Rng;
fn main() {
let secret_number = rand::thread_rng().gen_range(1..101);
}
嵌套路径来消除大量的use行
use std::cmp::Ordering;
use std::io;
// ---snip---
相反,我们可以使用嵌套路径将相同的项在一行中引入作用域。这么做需要指定路径的相同部分,接着是两个冒号,接着是大括号中的各自不同的路径部分,如示例 7-18 所示。
文件名: src/main.rs
use std::{cmp::Ordering, io};
通过glob运算符将所有公有定义引入作用域
如果希望将一个路径下 所有 公有项引入作用域,可以指定路径后跟 glob 运算符 *:
use std::collections::*;
4.将模块分割到不同的文件中
文件名: src/lib.rs
mod front_of_house; //在 mod front_of_house 后使用分号,而不是代码块,这将告诉 Rust 在另一个与模块同名的文件中加载模块的内容。子
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
文件名: src/front_of_house.rs
pub mod hosting {
pub fn add_to_waitlist() {}
}
继续重构
将 hosting 模块也提取到其自己的文件中,仅对 src/front_of_house.rs 包含 hosting 模块的声明进行修改:
文件名: src/front_of_house.rs
pub mod hosting;
接着我们创建一个 src/front_of_house 目录和一个包含 hosting 模块定义的 src/front_of_house/hosting.rs 文件:
文件名: src/front_of_house/hosting.rs
pub fn add_to_waitlist() {}
进阶- 常见集合
同于内建的数组和元组类型,这些集合指向的数据是储存在堆上的,这意味着数据的数量不必在编译时就已知,并且还可以随着程序的运行增长或缩小。每种集合都有着不同功能和成本,而根据当前情况选择合适的集合,这是一项应当逐渐掌握的技能。在这一章里,我们将详细的了解三个在 Rust 程序中被广泛使用的集合:
- vector 允许我们一个挨着一个地储存一系列数量可变的值
- 字符串(string)是字符的集合。我们之前见过
String类型,不过在本章我们将深入了解。 - 哈希 map(hash map)允许我们将值与一个特定的键(key)相关联。这是一个叫做 map 的更通用的数据结构的特定实现。
1.vector
let v: Vec<i32> = Vec::new();
let v = vec![1, 2, 3];//使用宏来创建
更新vector
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
vector 离开作用域后也会丢弃其所有元素
{
let v = vec![1, 2, 3, 4];
// 处理变量 v
} // <- 这里 v 离开作用域并被丢弃
读取vector的元素的两种方式
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {}", third);
match v.get(2) {
Some(third) => println!("The third element is {}", third),
None => println!("There is no third element."),
}
当引用一个不存在的元素时 Rust 会造成 panic。这个方法更适合当程序认为尝试访问超过 vector 结尾的元素是一个严重错误的情况,这时应该使程序崩溃。
当 get 方法被传递了一个数组外的索引时,它不会 panic 而是返回 None
当我们获取了 vector 的第一个元素的不可变引用并尝试在 vector 末尾增加一个元素的时候,这是行不通的:
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);//
println!("The first element is: {}", first);
编译会给出这个错误:
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {}", first);
| ----- immutable borrow later used here
代码看起来应该能够运行:为什么第一个元素的引用会关心 vector 结尾的变化?不能这么做的原因是由于 vector 的工作方式:在 vector 的结尾增加新元素时,在没有足够空间将所有所有元素依次相邻存放的情况下,可能会要求分配新内存并将老的元素拷贝到新的空间中。这时,第一个元素的引用就指向了被释放的内存。借用规则阻止程序陷入这种状况。
通过可变引用改变vector的值
我们也可以遍历可变 vector 的每一个元素的可变引用以便能改变他们。示例 中的 for 循环会给每一个元素加 50:
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
使用枚举来存储多种类型的值
本章的开始,我们提到 vector 只能储存相同类型的值。这是很不方便的;绝对会有需要储存一系列不同类型的值的用例。幸运的是,枚举的成员都被定义为相同的枚举类型,所以当需要在 vector 中储存不同类型值时,我们可以定义并使用一个枚举!
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
Rust 在编译时就必须准确的知道 vector 中类型的原因在于它需要知道储存每个元素到底需要多少内存。第二个好处是可以准确的知道这个 vector 中允许什么类型。
2.字符串String
Rust的核心部分中只有一种字符串类型,那就是字符串切片str, 它常以借用的形式出现(&str)
String 与&str
// &str 类型
let hello: &str = "Hello, world!";
// String 类型
let mut hello_string: String = String::from("Hello, world!");
//创建一个空字符串
let mut s = String::new();
// &str 转 String
let new_string = hello.to_string();
// String 转 &str
let new_str: &str = &hello_string;
// 修改 String
hello_string.push_str(" Rust is great!");
更新字符串
let mut s = String::from("foo");
s.push_str("bar");//push_str 方法采用字符串 slice,因为我们并不需要获取参数的所有权。
let mut s = String::from("lo");
s.push('l'); //单独字符
//使用 + 运算符将两个 String 值合并到一个新的 String 值中
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // 注意 s1 被移动了,不能继续使用
//使用format拼接 , format! 与 println! 的工作原理相同,不过不同于将输出打印到屏幕上,它返回一个带有结果内容的 String。
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{}-{}-{}", s1, s2, s3);
深入看看String
String 是一个 Vec<u8> 的封装。
遍历字符串
//如果你需要操作单独的 Unicode 标量值,最好的选择是使用 chars 方法。对 “नमस्ते” 调用 chars 方法会将其分开并返回六个 char 类型的值
for c in "नमस्ते".chars() {
println!("{}", c);
}
//bytes 方法返回每一个原始字节,这可能会适合你的使用场景:
for b in "नमस्ते".bytes() {
println!("{}", b);
}
3.存储键值对的hash map
创建一个hash map
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
像 vector 一样,哈希 map 将它们的数据储存在堆上,这个 HashMap 的键类型是 String 而值类型是 i32。类似于 vector,哈希 map 是同质的:所有的键必须是相同类型,值也必须都是相同类型。
另一个构建哈希 map 的方法是使用一个元组的 vector 的
collect方法,其中每个元组包含一个键值对。
use std::collections::HashMap;
let teams = vec![String::from("Blue"), String::from("Yellow")];
let initial_scores = vec![10, 50];
let scores: HashMap<_, _> = teams.iter().zip(initial_scores.iter()).collect();
**
teams.iter()和initial_scores.iter()**:使用.iter()方法在teams和initial_scores向量上创建了迭代器。这两个迭代器分别会生成&String和&i32类型的元素。zip(initial_scores.iter()):zip函数会将teams.iter()生成的迭代器和initial_scores.iter()生成的迭代器”压缩”在一起。具体来说,它会创建一个新的迭代器,每次迭代都会返回一个元组,该元组中的第一个元素来自teams.iter(),第二个元素来自initial_scores.iter()。所以,如果
teams = ["Blue", "Yellow"],initial_scores = [10, 50],那么zip函数将生成以下元组的迭代器:(&"Blue", &10), (&"Yellow", &50)。collect(): 这个方法会将迭代器中的所有元素收集到一个集合中。在这里,它将元组的迭代器转换成一个HashMap。HashMap<_, _>: 这里的类型注解意味着该HashMap的键和值的类型是由编译器推导的。因为zip生成的是(&String, &i32)类型的元组,HashMap的类型实际上是HashMap<&String, &i32>。
这里 HashMap<_, _> 类型标注是必要的,因为 collect 有可能当成多种不同的数据结构,而除非显式指定否则 Rust 无从得知你需要的类型。但是对于键和值的类型参数来说,可以使用下划线占位,而 Rust 能够根据 vector 中数据的类型推断出 HashMap 所包含的类型。
hashmap和所有权
对于像 i32 这样的实现了 Copy trait 的类型,其值可以拷贝进哈希 map。对于像 String 这样拥有所有权的值,其值将被移动而哈希 map 会成为这些值的所有者
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// 这里 field_name 和 field_value 不再有效,
// 尝试使用它们看看会出现什么编译错误!
访问hash map 中的值
可以通过get方法 通过 键来获取对应的值、
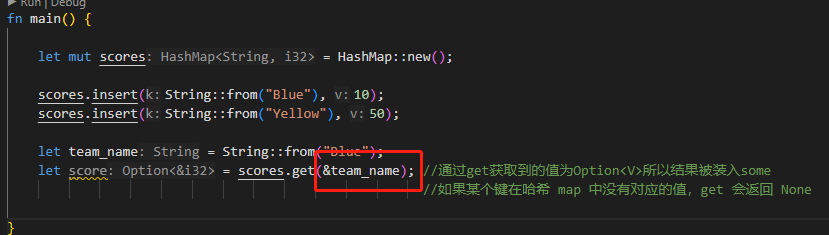
更新
覆盖:如果我们插入了一个键值对,接着用相同的键插入一个不同的值,与这个键相关联的旧值将被替换。即便
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
只在键没有对应值时插入
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
进阶- 错误处理
可恢复错误(recoverable)和 不可恢复错误(unrecoverable)。可恢复错误通常代表向用户报告错误和重试操作是合理的情况,比如未找到文件。不可恢复错误通常是 bug 的同义词,比如尝试访问超过数组结尾的位置。
panic! 与不可恢复的错误
有的时候代码出问题了,而你对此束手无策。对于这种情况,Rust 有 panic!宏。当执行这个宏时,程序会打印出一个错误信息,展开并清理栈数据,然后接着退出。出现这种情况的场景通常是检测到一些类型的 bug,而且开发者并不清楚该如何处理它。
result与可恢复错误
fn main() {
let f = File::open("hello.txt");//File::open 函数的返回值类型是 Result<T, E>
let f = match f {//当 File::open 成功的情况下,变量 f 的值将会是一个包含文件句柄的 Ok 实例。在失败的情况下,f 的值会是一个包含更多关于出现了何种错误信息的 Err 实例。
Ok(file) => file,//从OK中拆出来file
Err(error) => {
panic!("Problem opening the file: {:?}", error)
},
};
}
fn main() {
let f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {//如果是没有文件可以尝试创建文件
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {:?}", e),
},
other_error => panic!("Problem opening the file: {:?}", other_error),
},
};
}
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let f = File::open("hello.txt").unwrap_or_else(|error| {//如果正常就返回file 了否则继续执行代码
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Problem creating the file: {:?}", error);
})
} else {
panic!("Problem opening the file: {:?}", error);
}
});
}
失败时panic的简写: unwrap和expect
use std::fs::File;
fn main() {
let f = File::open("hello.txt").unwrap();
}
如果调用这段代码时不存在 hello.txt 文件,我们将会看到一个 unwrap 调用 panic!
use std::fs::File;
fn main() {
let f = File::open("hello.txt").expect("Failed to open hello.txt");
}
expect 与 unwrap 的使用方式一样:返回文件句柄或调用 panic! 宏。expect 在调用 panic! 时使用的错误信息将是我们传递给 expect 的参数,而不像 unwrap 那样使用默认的 panic! 信息。它看起来像这样:
thread 'main' panicked at 'Failed to open hello.txt: Error { repr: Os { code:
2, message: "No such file or directory" } }', src/libcore/result.rs:906:4
因为这个错误信息以我们指定的文本开始,Failed to open hello.txt,将会更容易找到代码中的错误信息来自何处。如果在多处使用 unwrap,则需要花更多的时间来分析到底是哪一个 unwrap 造成了 panic,因为所有的 unwrap 调用都打印相同的信息。
错误的传播
当编写一个需要先调用一些可能会失败的操作的函数时,除了在这个函数中处理错误外,还可以选择让调用者知道这个错误并决定该如何处理。这被称为 传播(propagating)错误,这样能更好地控制代码调用,因为比起你代码所拥有的上下文,调用者可能拥有更多信息或逻辑来决定应该如何处理错误。
use std::io;
use std::io::Read;
use std::fs::File;
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("hello.txt");
let mut f = match f {
Ok(file) => file, //如果能正常打开文件的话就将file赋值给f
Err(e) => return Err(e),
};
let mut s = String::new();
match f.read_to_string(&mut s) { //将f指向的文件第一行读给s,成功返回s
Ok(_) => Ok(s),
Err(e) => Err(e),
}
}
函数的返回值:Result<String, io::Error> 这意味着函数返回一个 Result<T, E> 类型的值,其中泛型参数 T 的具体类型是 String,而 E 的具体类型是 io::Error
调用这个函数的代码最终会得到一个包含用户名的 Ok 值,或者一个包含 io::Error 的 Err 值。
传播错误的简写: ? 运算符
use std::io;
use std::io::Read;
use std::fs::File;
fn read_username_from_file() -> Result<String, io::Error> {
let mut f = File::open("hello.txt")?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
如果 Result 的值是 Ok,这个表达式将会返回 Ok 中的值而程序将继续执行。如果值是 Err,Err 将作为整个函数的返回值
the ? operator can only be used in a function that returns Result or Option (or another type that implements FromResidual)
进阶- 泛型、trait 与生命周期
泛型是具体类型或其他属性的抽象替代。我们可以表达泛型的属性,比如他们的行为或如何与其他泛型相关联,而不需要在编写和编译代码时知道他们在这里实际上代表什么。
泛型
我们要实现寻找slice最大值的函数
fn largest_i32(list: &[i32]) -> i32 {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> char {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
每一个类型都写一个函数太麻烦了, 引入泛型
fn largest<T>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
可以这样理解这个定义:函数 largest 有泛型类型 T。它有个参数 list,其类型是元素为 T 的 slice。largest 函数的返回值类型也是 T。
当然,这个代码还是无法通过编译,简单来说,这个错误表明 largest 的函数体不能适用于 T 的所有可能的类型。因为在函数体需要比较 T 类型的值,不过它只能用于我们知道如何排序的类型。
结构体中的泛型
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}
其语法类似于函数定义中使用泛型。首先,必须在结构体名称后面的尖括号中声明泛型参数的名称。接着在结构体定义中可以指定具体数据类型的位置使用泛型类型。
注意 Point<T> 的定义中只使用了一个泛型类型,这个定义表明结构体 Point<T> 对于一些类型 T 是泛型的,而且字段 x 和 y 都是 相同类型的,无论它具体是何类型。如果尝试创建一个有不同类型值的 Point<T> 的实例 将无法通过编译。
如果想要定义一个 x 和 y 可以有不同类型且仍然是泛型的 Point 结构体,我们可以使用多个泛型类型参数。
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}
方法定义中的泛型
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}
注意必须在 impl 后面声明 T,这样就可以在 Point<T> 上实现的方法中使用它了, impl 之后声明泛型 T ,这样 Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。
struct Point<T, U> {
x: T,
y: U,
}
impl<T, U> Point<T, U> {
fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c'};
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}
这个例子的目的是展示一些泛型通过 impl 声明而另一些通过方法定义声明的情况。这里泛型参数 T 和 U 声明于 impl 之后,因为他们与结构体定义相对应。而泛型参数 V 和 W 声明于 fn mixup 之后,因为他们只是相对于方法本身的
trait: 定义共享行为
一个类型的行为由其可供调用的方法构成。如果可以对不同类型调用相同的方法的话,这些类型就可以共享相同的行为了。trait 定义是一种将方法签名组合起来的方法,目的是定义一个实现某些目的所必需的行为的集合。
trait 类似于其他语言中常被称为 接口(interfaces)的功能,虽然有一些不同。
//定义一个trait
pub trait Summary {
fn summarize(&self) -> String; //描述实现这个trait的类型所需要的行为的方法签名。
}
//然后为类型实现trait
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
调用trait
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know, people"),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
trait作为参数传递
pub fn notify(item: impl Summary) {
println!("Breaking news! {}", item.summarize());
}
对于 item 参数,我们指定了 impl 关键字和 trait 名称,而不是具体的类型。
trait bound
pub fn notify<T: Summary>(item: T) {
println!("Breaking news! {}", item.summarize());
}
通过+ 指定多个trait
pub fn notify(item: impl Summary + Display) {
+ 语法也适用于泛型的 trait bound:
pub fn notify<T: Summary + Display>(item: T) {
通过where 简化trait bound:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: T, u: U) -> i32 {...
fn some_function<T, U>(t: T, u: U) -> i32
where T: Display + Clone,
U: Clone + Debug
{
返回值实现trait
fn returns_summarizable() -> impl Summary {
Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know, people"),
reply: false,
retweet: false,
}
}
修改获取最大值代码
//一个可以用于任何实现了 PartialOrd 和 Copy trait 的泛型的 largest 函数
fn largest<T: PartialOrd + Copy>(list: &[T]) -> T {
//为了只对实现了 Copy 的类型调用这些代码,可以在 T 的 trait bounds 中增加 Copy
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
生命周期与引用的有效性
类似于当因为有多种可能类型的时候必须注明类型,也会出现引用的生命周期以一些不同方式相关联的情况,所以 Rust 需要我们使用泛型生命周期参数来注明他们的关系,这样就能确保运行时实际使用的引用绝对是有效的。
生命周期避免了垂直引用
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
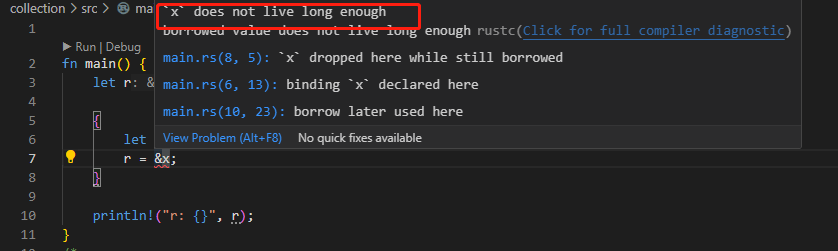
函数中泛型的生命周期
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
该函数 fn longest(x: &str, y: &str) -> &str 在 Rust 中不能通过编译,因为它违反了 Rust 的生命周期规则。具体来说,该函数没有明确指出返回值的生命周期是如何与输入参数 x 和 y 的生命周期关联的。
当你返回一个引用(在这里是 &str),Rust 需要知道这个引用的“生命周期”——即引用的数据将保持有效多长时间。在这个函数的上下文中,返回的字符串切片(&str)可能是 x 或 y,并且它的有效期需要与输入参数 x 或 y 的有效期相匹配。
你可以通过生命周期标注来修复这个问题,以明确指出输入参数和返回值之间的生命周期关系:
rustCopy codefn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
在这里,'a 是一个生命周期标注,它表明参数 x 和 y 必须具有相同的生命周期 'a,并且返回值也将具有同样的生命周期 'a。这意味着:
x和y必须有相同的生命周期。- 返回的引用(不论是
x还是y)也将有相同的生命周期。
这样,Rust 的生命周期检查器就能确保你的代码是安全的。
需要注意的是,这样的函数有一定的限制。例如,它不能接受具有不同生命周期的 x 和 y 参数。但这些限制是由你函数的逻辑和需求决定的。根据你的具体需求,这样的限制可能是完全可接受的,也可能需要进一步优化。
引用的 生命周期标注语法
生命周期标注描述了多个引用生命周期相互的关系,而不影响其生命周期。
生命周期参数名称必须以撇号(')开头,其名称通常全是小写,类似于泛型其名称非常短。
'a 是大多数人默认使用的名称。生命周期参数标注位于引用的 & 之后,并有一个空格来将引用类型与生命周期标注分隔开。
&i32 // 引用
&'a i32 // 带有显式生命周期的引用
&'a mut i32 // 带有显式生命周期的可变引用
单个生命周期标注本身没有多少意义,因为生命周期标注告诉 Rust 多个引用的泛型生命周期参数如何相互联系的。
函数签名中的生命周期标注:
泛型生命周期参数需要生命在函数名和参数列表间的尖括号中。 & str -> &’a str
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
当具体的引用被传递给 longest时 ,被 ‘a 所替代的具体生命周期是x的作用域与y的作用域相重叠的那部分。
或者说 泛型生命周期 ‘a 的具体生命周期等同于x和y的生命周期中较小的 那一个。
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {}", result);
}
// println!("The longest string is {}", result); 如果在这输出就不对了,因为超出了string的作用域
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
结构体定义中引用的生命周期标注
在结构体中定义slice时,我们也需要考虑其生命周期的问题
struct ImportantExcerpt<'a> {
part: &'a str, // part不使用之前, 结构体实例必须已经不被使用了
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.')
.next()
.expect("Could not find a '.'");
let i = ImportantExcerpt { part: first_sentence };
}
这个结构体有一个字段,part,它存放了一个字符串 slice,这是一个引用。
类似于泛型参数类型,必须在结构体名称后面的尖括号中声明泛型生命周期参数,以便在结构体定义中使用生命周期参数。
这个标注意味着ImportantExcept 的实例不能比其part字段中的引用存在的更久
生命周期省略
函数或方法的参数的生命周期被称为 输入生命周期(input lifetimes),而返回值的生命周期被称为 输出生命周期(output lifetimes)。
第一条规则是每一个是引用的参数都有它自己的生命周期参数。换句话说就是,有一个引用参数的函数有一个生命周期参数:fn foo<'a>(x: &'a i32),有两个引用参数的函数有两个不同的生命周期参数,fn foo<'a, 'b>(x: &'a i32, y: &'b i32),依此类推。
第二条规则是如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数:fn foo<'a>(x: &'a i32) -> &'a i32。
第三条规则是如果方法有多个输入生命周期参数并且其中一个参数是 &self 或 &mut self,说明是个对象的方法(method), 那么所有输出生命周期参数被赋予 self 的生命周期。第三条规则使得方法更容易读写,因为只需更少的符号。
静态生命周期
这里有一种特殊的生命周期值得讨论:'static,其生命周期能够存活于整个程序期间。所有的字符串字面量都拥有 'static 生命周期,我们也可以选择像下面这样标注出来:
let s: &'static str = "I have a static lifetime.";
这个字符串的文本被直接储存在程序的二进制文件中而这个文件总是可用的。因此所有的字符串字面量都是 'static 的。
实现一个Grep
main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
//通过minigrep库的Config函数来将参数读入config
let config = Config::new(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {}", err);
process::exit(1);
});
//通过minigrep库的run函数
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {}", e);
process::exit(1);
}
}
rintln!("{:?}",args);
}
lib.rs
use std::error::Error;
use std::fs;
use std::env;
pub struct Config {
pub query: String,
pub filename: String,
pub case_sensitive: bool,
}
impl Config {
pub fn new(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let filename = args[2].clone();
let case_sensitive = env::var("CASE_INSENSITIVE").is_err();
Ok(Config { query, filename, case_sensitive })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.filename)?;
let results = if config.case_sensitive {
search(&config.query, &contents)
} else {
search_case_insensitive(&config.query, &contents)
};
for line in results {
println!("{}", line);
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {//函数返回值的生命周期必须和contents一样长
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(
vec!["safe, fast, productive."],
search(query, contents)
);
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Rust 中的函数式语言功能:迭代器与闭包
我们将要涉及:
- 闭包(Closures),一个可以储存在变量里的类似函数的结构
- 迭代器(Iterators),一种处理元素序列的方式
- 如何使用这些功能来改进 minigrep
- 这两个功能的性能(剧透警告: 他们的速度超乎你的想象!)
1.闭包: 可以捕获其环境的匿名函数
- Rust 的 闭包(closures)是可以保存进变量或作为参数传递给其他函数的匿名函数。
- 可以在一个地方创建闭包,然后在不同的上下文中执行闭包运算。
- 不同于函数,闭包允许捕获调用者作用域中的值。
考虑一下这个假定的场景:我们在一个通过 app 生成自定义健身计划的初创企业工作。其后端使用 Rust 编写,而生成健身计划的算法需要考虑很多不同的因素,比如用户的年龄、身体质量指数(Body Mass Index)、用户喜好、最近的健身活动和用户指定的强度系数。本例中实际的算法并不重要,重要的是这个计算将会花费几秒钟。我们只希望在需要时调用算法,并且只希望调用一次,这样就不会让用户等得太久。
我们使用sleep函数来 模拟这个几秒的运算
use std::thread;
use std::time::Duration;
fn simulated_expensive_calculation(intensity: u32) -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
intensity
}
main函数中 ,为了简便表示我们硬编码了两个用户的参数,通过generate_workout 传入这两个用户参数 ,
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(
simulated_user_specified_value,
simulated_random_number
);
}
在generate_workout内部调用simulated_expensive_calculation
fn generate_workout(intensity: u32, random_number: u32) {
if intensity < 25 {
println!(
"Today, do {} pushups!",
simulated_expensive_calculation(intensity)
);
println!(
"Next, do {} situps!",
simulated_expensive_calculation(intensity)
); //这里调用了两次
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");//这里没有调用
} else {
println!(
"Today, run for {} minutes!",
simulated_expensive_calculation(intensity)
//这里调用了一次
);
}
}
}
现在这份代码能够应对我们的需求了,但数据科学部门的同学告知我们将来会对调用 simulated_expensive_calculation 的方式做出一些改变。为了在要做这些改动的时候简化更新步骤,我们将重构代码来让它只调用 simulated_expensive_calculation 一次。同时还希望去掉目前多余的连续两次函数调用,并不希望在计算过程中增加任何其他此函数的调用。
也就是说,我们不希望在完全无需其结果的情况调用函数,在必要时也最多只调用一次。
有多种方法可以重构此程序。我们首先尝试的是将重复的
simulated_expensive_calculation函数调用提取到一个变量中,
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_result =
simulated_expensive_calculation(intensity);//调用一次
if intensity < 25 {
println!(
"Today, do {} pushups!",
expensive_result
);
println!(
"Next, do {} situps!",
expensive_result
);
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_result
);
}
}
}
不幸的是,现在所有的情况下都需要调用函数并等待结果,包括那个完全不需要这一结果的内部 if 块。
我们希望能够在程序的一个位置指定某些代码,并只在程序的某处实际需要结果的时候 执行 这些代码。这正是闭包的用武之地!
不同于总是在
if块之前调用simulated_expensive_calculation函数并储存其结果,我们可以定义一个闭包并将其储存在变量中
let expensive_closure = |num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
}
闭包的定义以一对竖线(|)开始,在竖线中指定闭包的参数;这个闭包有一个参数 num;如果有多于一个参数,可以使用逗号分隔,比如 |param1, param2|。
参数之后是存放闭包体的大括号 —— 如果闭包体只有一行则大括号是可以省略的。在闭包的末尾,花括号之后,需要使用分号使 let 语句完整。因为闭包体的最后一行没有分号(正如函数体一样),所以闭包体(num)最后一行的返回值作为调用闭包时的返回值 。
注意这个 let 语句意味着 expensive_closure 包含一个匿名函数的 定义,不是调用匿名函数的 返回值。
定义了闭包之后,可以改变 if 块中的代码来调用闭包以执行代码并获取结果值。调用闭包类似于调用函数。
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!(
"Today, do {} pushups!",
expensive_closure(intensity)
);
println!(
"Next, do {} situps!",
expensive_closure(intensity)
); //
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure(intensity)
);
}
}
}
仍然在第一个 if 块中调用了闭包两次,这调用了慢计算代码两次而使得用户需要多等待一倍的时间。可以通过在 if 块中创建一个本地变量存放闭包调用的结果来解决这个问题,不过闭包可以提供另外一种解决方案。
闭包有默认的类型标注,我们看看一个简单的函数是如何转换成闭包的
fn add_one_v1 (x: u32) -> u32 { x + 1 } //函数
let add_one_v2 = |x: u32| -> u32 { x + 1 };//完整的闭包
let add_one_v3 = |x| { x + 1 };// 省略类型标注
let add_one_v4 = |x| x + 1 ;//去掉了大括号
闭包定义会为每个参数和返回值推断一个具体类型,如果尝试对同一闭包使用不同类型则会得到类型错误。
幸运的是,还有另一个可用的方案。可以创建一个存放闭包和调用闭包结果的结构体。该结构体只会在需要结果时执行闭包,并会缓存结果值,这责保存结果并可以复用该值。你可能见过这种模式被称 memoization 或 lazy evaluation (惰性求值)。
为了让结构体存放闭包,我们需要指定闭包的类型,因为结构体定义需要知道其每一个字段的类型。每一个闭包实例有其自己独有的匿名类型:也就是说,即便两个闭包有着相同的签名,他们的类型仍然可以被认为是不同。为了定义使用闭包的结构体、枚举或函数参数,需要使用 trait bound 和泛型
参考文章
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com