资料参考
https://waylandzhang.github.io/en/let-s-code-llm.html
https://discuss.pytorch.org/t/quantization-aware-training-for-gpt2/138738
https://www.bilibili.com/video/BV1VF4m1c7uq
https://space.bilibili.com/12420432
https://zhuanlan.zhihu.com/p/78153185
https://github.com/waylandzhang/Transformer-from-scratch/blob/master/model.py
相关准备
安装用到的库
uv venv --python 3.11
uv init
source .venv/
source .venv/bin/activate
uv add numpy requests torch tiktoken matplotlib pandas
导入包
import os
import requests
import pandas as pd
import matplotlib.pyplot as plt
import math
import tiktoken
import torch
import torch.nn as nn
超参数设置
context_length=256# 上下文长度
d_model=256 # 嵌入向量的维度
num_block=12 # Transformer块数
num_heads=8 # 多头注意力的头数
整体分析
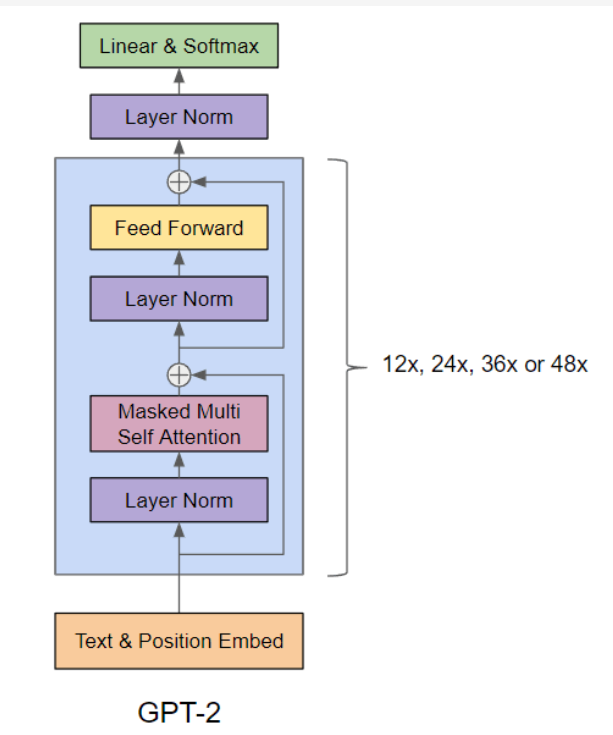
流程概述
- 用户的输入是文本,如[‘今‘,’天’,’天‘,’气’]
- Tokennizer:使用Tokenizer对其进行Token化,每一个字都与一个tokenid一一对应[‘今‘,’天’,’天‘,’气’] -> [222,123,323,414],注意这里只是一个简单的介绍,实际上的字符数量和token数量并不一定相等
- Embedding:然后是向量化,token id 之间并没有语义上的联系,他更像是一个词典的目录,那么如何获取其具体的意思呢?我们可以将其向量化,即每一个token id 对应一个高维度的向量,通过训练学习,词向量学习到词的语义以及词与词之间的关系。假设向量维度为256,[222,123,323,414] -> [4,256] 即四个token,每一个对应一个256维度的向量。
- Position Embedding:给向量加上位置编码,让其有位置的概念
- Attention:一个词的语义并不是固定的,如苹果可能是水果,也可能是科技公司,它的实际语义是根据上下文进行决定的,注意力机制会让原始的词向量了解到上下文,根据语境对自己进行进一步的调整,最终这个词向量会学习到带有上下文的语义。
- 预测:模型的目的是,根据当前词预测下一个词(next token),因此输入[‘今‘,’天’,’天‘,’气’],理想的模型处理后输出应该是[‘天’,’天‘,’气’,’怎’]每一个token经过模型处理后,会预测出下一个词。
模块概述
Tokenizer: 将自然语言文本一一映射为一个token id
Embedding:将token id向量化,通过学习,每一个词向量都有自己正确的语义。
Position Embedding: 位置编码,让向量拥有位置的概念,如果没有位置[‘今‘,’天’,’天‘,’气’]中的两个天的向量在后续注意力计算中,值是相同的。
Attention: 让词向量学习到正确的上下文,使其具有更丰富、更正确的语义(如下图,通过Attention,结合上下文词向量学习到更正确的语义)

代码分析
import math
import tiktoken
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchinfo
context_length=256# 上下文长度
d_model=256 # 嵌入向量的维度
num_block=12 # Transformer块数
num_heads=8 # 多头注意力的头数
Tokenizer
- 在自然语言处理中,token 是文本的基本单位。它可以是单词、单词的一部分或者标点符号
- Tokenizer 负责将文本转换成数字id
- tiktoken 是 OpenAI 开发的一种快速 BPE(字节对编码)分词器。BPE 将单词拆分成子词,因此一个单词可能被拆分成多个 token。例如,“unbelievable”可能被拆分成“un”、“believe”和“able”三个 token。
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
encoding.encode("今天天气怎么样")
#[37271, 36827, 36827, 30320, 242, 17486, 236, 82696, 91985]
Token Embedding Table
接下来是GPT架构的模块分析了,首先是模型的输入和输出
- 输入的是tokenid ,需要将这个数字转换成一个高维度的词向量,这就用到了 Embedding
token_embedding=nn.Embedding(max_token_value,d_model)
这个仅需要一行代码,会放到最终的Model类里面max_token_value=max(tokenized_text)+1
其本质是一个查找表,输入为整形的token id, 输出为对应的维度为d_model的向量,这个表通常为几千到十几万。
假设表大小为50257,词向量维度d_model为768,则这一部分的参数量为38,597,376, 38M
- 输出部分,需要将词向量转换成tokenid ,这一步主要是用了Feed Forward + softmax
language_model_out_linear_layer = nn.Linear(in_features=self.d_model, out_features=self.max_token_value)
Transformer块 整体分析
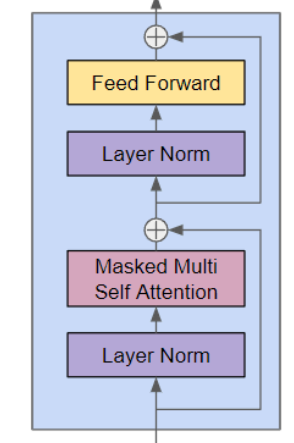
Transformer块是GPT2的核心部分,整个模型中包含多个Transformer块,Transformer块的输入和输出相同,输入通过多个Transformer块后,每个Token都学习到上下文,进而做出next token预测
Transformer块有两个主要部分:Masked Multi Self Attention 和 Feed Forward
- 通过Attention
FeedForward
class FeedForwardNetWork(nn.Module):
def __init__(self,d_model,d_ff):
super().__init__()
self.d_model=d_model
self.d_ff=d_ff
self.ffn=nn.Sequential(
nn.Linear(in_features=self.d_model,out_features=self.d_ff),
nn.ReLU(),
nn.Linear(in_features=self.d_ff,out_features=self.d_model),
nn.Dropout(0.1)
)
def forward(self,x):
return self.ffn(x)
d_model的四倍就是 d_ff ,可以理解为首先将向量放大维度,随后将其缩小到原来的维度
通过两层线性变换和中间的非线性激活函数(如ReLU)Linear → ReLU → Linear,引入了更强的非的非线性关系。
ScaledDotProductAttention
Masked Multi Self Attention 可以理解为多个ScaledDotProductAttention组成的模块,我们先看一下 ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
def __init__(self,head_dim,context_length=16,dropout=0.1):
super().__init__()
self.head_dim=head_dim
self.dropout=dropout
self.Wq=nn.Linear(head_dim,head_dim,bias=False)
self.Wk=nn.Linear(head_dim,head_dim,bias=False)
self.Wv=nn.Linear(head_dim,head_dim,bias=False)
self.context_length=context_length
# apply mask
self.register_buffer('mask',torch.tril(torch.ones(context_length,context_length)))
self.dropout_layer = nn.Dropout(self.dropout)
def forward(self,x):
B,T,C=x.shape
assert T<=self.context_length
assert C==self.head_dim
Q=self.Wq(x)
K=self.Wk(x)
V=self.Wv(x)
#计算分数
attention=Q @ K.transpose(-2,-1) / math.sqrt(self.head_dim)
# mask
attention=attention.masked_fill(self.mask[:T,:T]==0,float('-inf'))
attention_score=F.softmax(attention,dim=-1)
x=attention_score@V
return x
模块定义了 Wq Wk Wv三个矩阵,通过与输入进行计算获取到对应的Q , K , V。
Wq Query 负责提取词向量需要什么 -> Q
Wk Key 负责提取词向量拥有什么 -> K
Wv Value 负责提取词向量拥有的那些具体的东西 -> V
Q与K之间的运算可以理解为向量之间相互查找匹配,并对其他向量的关注度进行打分,关注度高的会打高分,这就是注意力得分,如果有10个词输入,则获得一个10x10的矩阵,代表互相之间的打分
要注意的是,GPT2在训练的时候,是要根据当前词预测下一个词,虽然输入的是10个词,但第一个词总不可能上来就知道后续哪些词,因此即使对后续词有很高的关注度,在打分时也需要将分数值设为0。
将一个词给其他词注意力得分与V相乘,这样每一个词都或多或少参与了最终词向量的构建。
Masked Multi Self Attention
如果只使用ScaledDotProductAttention ,词向量学习不到足够多的特征,因此GPT2使用了多头掩码自注意力机制,可以理解为首先将向量的维度进行拆分,将拆分的向量分别通过不同的ScaledDotProductAttention来进行上下文学习,随后汇聚到一起。
class MultiHeadAttention(nn.Module):
def __init__(self,d_model,num_heads,context_length=16):
super().__init__()
self.d_model=d_model
self.num_heads=num_heads
self.context_length=context_length
self.head_dim=d_model // num_heads
self.heads=nn.ModuleList([ScaledDotProductAttention(head_dim=d_model//num_heads,context_length=context_length) for _ in range(num_heads)])
self.projection_layer=nn.Linear(d_model,d_model)
self.dropout=nn.Dropout(0.1)
def forward(self,x):
# 将x拆分成多头
batch_size=x.size(0)
# view : 对数据重新分组,平铺后的矩阵数据位置还是一样的
# transpose:x[a,b]的访问变为x[b,a]数据肯定是被打乱的了
x=x.view(batch_size,-1,self.num_heads,self.head_dim).transpose(1,2)
heads_output=[]
for i,head in enumerate(self.heads):
heads_output.append(head(x[:,i]))
heads_output=torch.cat(heads_output,dim=-1)
out=self.projection_layer(heads_output)
out=self.dropout(out)
return out
首先将向量进行切分,分别调用ScaledDotProductAttention ,将结果进行合并。通过一个线性层后作最终结果返回。
TransFormerBlock
有了前面两个模块后就可以封装一个完整的TransformerBlock了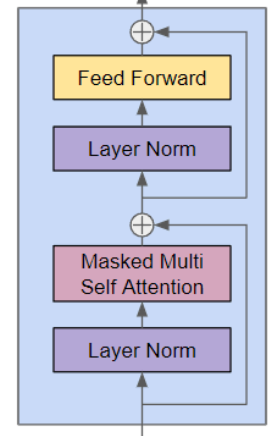
class TransformerBlock(nn.Module):
def __init__(self,d_model,num_heads,context_length=16):
super().__init__()
self.d_model=d_model
self.num_heads=num_heads
self.layer_norm1=nn.LayerNorm(d_model)
self.layer_norm2=nn.LayerNorm(d_model)
self.multi_head_attention =MultiHeadAttention(d_model=d_model,num_heads=num_heads,context_length=context_length)
self.ff_network=FeedForwardNetWork(d_model=d_model,d_ff=4*d_model)
def forward(self,x):
multi_attention_output=self.multi_head_attention(x)
x=self.layer_norm1(x+multi_attention_output)
feed_forward_output=self.ff_network(x)
x=self.layer_norm2(x+feed_forward_output)
return x
- layerNorm 对单个样本的所有特征维度归一化,解决了深度网络训练中的分布不稳定问题。
- 残差结构x=x+Attention(LayerNorm(x)) x=x+FFN(LayerNorm(x))
GPT2Model
最后将以上模块进行整合
class GPT2Model(nn.Module):
def __init__(self,max_token_value,d_model,num_heads,num_blocks,context_length=16):
super().__init__()
self.d_model=d_model
self.context_length=context_length
self.token_embedding=nn.Embedding(max_token_value,d_model)
self.transformer_block=nn.Sequential(*([TransformerBlock(d_model=d_model,num_heads=num_heads,context_length=context_length) for _ in range(num_blocks)]+[nn.LayerNorm(self.d_model)]))
self.language_model_out_linear_layer = nn.Linear(in_features=self.d_model, out_features=max_token_value)
def forward(self,idx,targets=None):
B,T=idx.shape
position_encoding_lookup_table = torch.zeros(self.context_length, self.d_model)
position = torch.arange(0, self.context_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, self.d_model, 2).float() * (-math.log(10000.0) / self.d_model))
position_encoding_lookup_table[:, 0::2] = torch.sin(position * div_term)
position_encoding_lookup_table[:, 1::2] = torch.cos(position * div_term)
# change position_encoding_lookup_table from (context_length, d_model) to (T, d_model)
position_embedding = position_encoding_lookup_table[:T, :].to(idx.device)
x=self.token_embedding(idx)+position_embedding
x=self.transformer_block(x)
logits=self.language_model_out_linear_layer(x) # batch_size , time_stamp ,table
if targets is not None:
B,T,C = logits.shape
logits_reshape=logits.view(B*T,C)
targets_reshape=targets.view(B*T)
loss=F.cross_entropy(input=logits_reshape,target=targets_reshape)
else:
loss=None
return logits,loss
def generate(self,idx,max_new_tokens=100):
for _ in range(max_new_tokens):
idx_crop = idx[:, -self.context_length:]
logits,loss=self(idx_crop)
logist_last_timestep=logits[:,-1,:]
probs=F.softmax(input=logist_last_timestep,dim=-1)
idx_next=torch.multinomial(input=probs,num_samples=1)
idx =torch.cat((idx,idx_next),dim=1)
return idx
文章参考:
博客地址: qwrdxer.github.io
欢迎交流: qq1944270374
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com