Unsloth
https://github.com/unslothai/unsloth
什么是Unsloth?
Unsloth 是一个专注于加速大语言模型(LLM)微调过程的开源框架,通过智能优化算法和内存管理技术,显著提升训练效率并降低资源消耗。
核心特性
- ⚡ 2-5倍训练加速 优化底层计算图与自动梯度检查点
- 💾 减少70%显存占用 智能张量分页与LoRA适配器优化
- 🔌 即插即用兼容性 支持HuggingFace生态,无需重写训练代码
- 🦙 主流模型支持 优化Llama、Mistral、Phi等架构
环境配置
非root用户安装cuda和cudnn参考:
https://zhuanlan.zhihu.com/p/198161777
下载对应的
https://developer.nvidia.com/rdp/cudnn-archive
安装cuda
chmod +x ./cuda_12.8.0_570.86.10_linux.run
sh ./cuda_12.8.0_570.86.10_linux.run
只安装 toolkit ,修改安装路径
配置环境变量
export CUDA_HOME=/data02/zah-workspace/cudaenv-12.4:$CUDA_HOME
export PATH=/data02/zah-workspace/cudaenv-12.4/bin:$PATH
export LD_LIBRARY_PATH=/data02/zah-workspace/cudaenv-12.4/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=$CUDA_HOME:/data02/zah-workspace/cudaenv-12.4
export PATH=$PATH:/data02/zah-workspace/cudaenv-12.4/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data02/zah-workspace/cudaenv-12.4/lib64
解压cudnn
tar -xJf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
cp cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/cudnn.h ./cudaenv-12.4/include/
cp cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/libcudnn* ./cudaenv-12.4/lib64/
chmod a+r ./cudaenv-12.4/include/cudnn.h ./cudaenv-12.4/lib64/libcudnn*
conda create --name zah_unsloth_env python=3.11
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu121
pip install unsloth --extra-index-url https://download.pytorch.org/whl/cu123
cu121onlytorch251
conda create --name zah_unsloth_env python=3.11 pytorch-cuda=12.1 pytorch cudatoolkit xformers
# 安装指定版本的torch https://pytorch.org/get-started/previous-versions/
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121
# 安装指定版本的 vllm https://docs.vllm.ai/en/latest/getting_started/installation/gpu/index.html#build-from-source
git clone https://github.com/vllm-project/vllm.git
cd vllm
python use_existing_torch.py
pip install -r requirements-build.txt
pip install -e . --no-build-isolation
# 安装指定版本的unsloth
pip install "unsloth[cu124-torch251] @ git+https://github.com/unslothai/unsloth.git"
配置好了 chda12.4直接安装即可
pip install vllm unsloth
开始训练
参考
https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb
设置只使用一个GPU
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1" # 仅使用 GPU 0
基本包导入,基本设置
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
from unsloth import is_bfloat16_supported
import torch
max_seq_length = 512 # Can increase for longer reasoning traces
lora_rank = 32 # Larger rank = smarter, but slower
加载基本模型 llama3
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "meta-llama/meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True, # False for LoRA 16bit
fast_inference = True, # Enable vLLM fast inference
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.6, # Reduce if out of memory
)
已经配置好基本的lora了
![[Pasted image 20250415123019.png]]
数据集加载
import re
from datasets import load_dataset, Dataset
# Load and prep dataset
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
#- 作用:从XML格式的文本中提取`<answer>`标签内的内容
#- 示例:对于输入`"<reasoning>...</reasoning><answer>42</answer>"`,返回`"42"`
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
# 作用:从包含`####`标记的文本中提取答案部分
# 示例:对于输入`"...#### 42"`,返回`"42"`
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split] # type: ignore
data = data.map(lambda x: { # type: ignore
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
}) # type: ignore
return data # type: ignore
dataset = get_gsm8k_questions()
数据大概是这个样子
{'question': 'Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?', 'answer': '10', 'prompt': [{'content': '\nRespond in the following format:\n<reasoning>\n...\n</reasoning>\n<answer>\n...\n</answer>\n', 'role': 'system'}, {'content': 'Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?', 'role': 'user'}]}
奖励函数
# Reward functions
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
这是用deepseek生成的 函数描述
correctness_reward_func(prompts, completions, answer)- 作用:评估回答的正确性
- 评分标准:
- 如果提取的回答与标准答案完全匹配,得2分
- 否则得0分
- 还会打印问题、标准答案、模型响应和提取的答案用于调试
int_reward_func(completions)- 作用:检查回答是否为纯数字
- 评分标准:
- 如果提取的回答是纯数字,得0.5分
- 否则得0分
strict_format_reward_func(completions)- 作用:严格检查XML格式
- 评分标准:
- 使用严格的正则表达式匹配完整的XML格式(包括换行)
- 符合格式得0.5分
soft_format_reward_func(completions)- 作用:宽松检查XML格式
- 评分标准:
- 使用更宽松的正则表达式匹配XML标签
- 符合格式得0.5分
count_xml(text)- 作用:细粒度评估XML格式质量
- 评分标准(累积得分):
- 每个正确的开始/结束标签得0.125分(共4个标签,最多0.5分)
- 对
</answer>后的多余文本进行惩罚(每字符减0.001分)
xmlcount_reward_func(completions)- 作用:应用
count_xml函数计算每个回答的XML格式得分
- 作用:应用
配置 训练参数
from trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(
use_vllm = True, # use vLLM for fast inference!
learning_rate = 5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type = "cosine",
optim = "paged_adamw_8bit",
logging_steps = 1,
bf16 = is_bfloat16_supported(),
fp16 = not is_bfloat16_supported(),
per_device_train_batch_size = 1,
gradient_accumulation_steps = 1, # Increase to 4 for smoother training
num_generations = 6, # Decrease if out of memory
max_prompt_length = 256,
max_completion_length = 200,
# num_train_epochs = 1, # Set to 1 for a full training run
max_steps = 250,
save_steps = 250,
max_grad_norm = 0.1,
report_to = "none", # Can use Weights & Biases
output_dir = "outputs",
)
创建训练器 并开始训练
指定模型、 Tokenizer 、 奖励函数 、训练参数 、数据集
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs = [
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args = training_args,
train_dataset = dataset,
)
trainer.train()
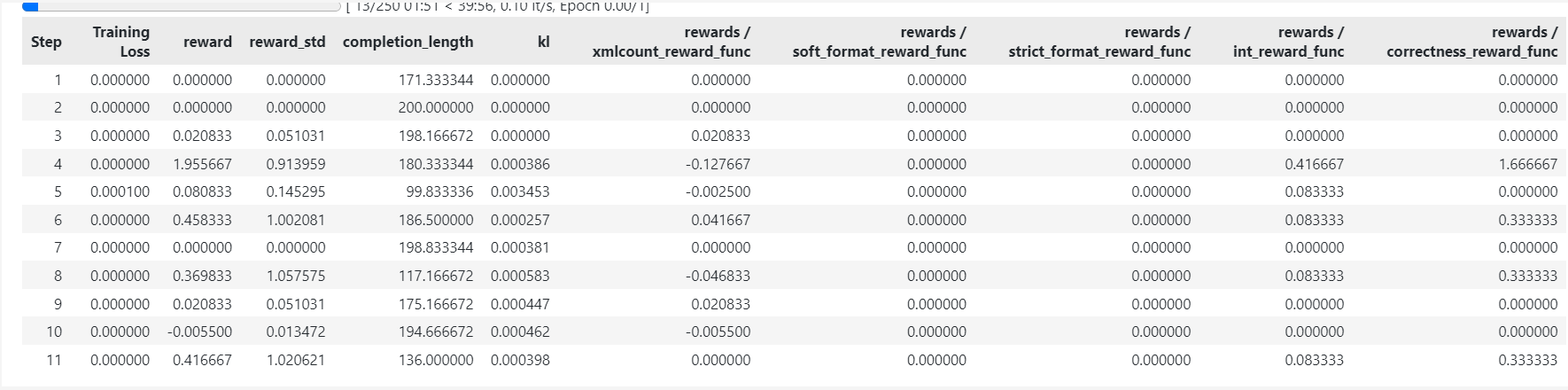
测试
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
text = tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT},
{"role" : "user", "content" : "calculate 11111 * 111"},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
[text],
sampling_params = sampling_params,
lora_request = None,
)[0].outputs[0].text
output
<math operation>
To calculate 11111 * 111, we can multiply the numbers directly.
11111 * 100 = 1111111
11111 * 10 = 111110
11111 * 1 = 11111
Now, sum the results of these multiplications to get the final answer.
</math operation>
<answer>
11111 * 111 = 1234321
</answer>'
模型保存
# 保存lora
model.save_lora("grpo_saved_lora")
# 保存训练好的模型
model.save_pretrained_merged("model", tokenizer, save_method = "merged_16bit",)
文章参考:
博客地址: qwrdxer.github.io
欢迎交流: qq1944270374
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com