简介
为了提高模型的准确率、需要大量高质量的数据。针对大模型攻防领域,恶意prompt具有稀缺性、同时模型训练对数据质量也有一定要求,因此需要进行数据工程。主要是两部份:
- 数据处理:攻击类型有多种,需要分类管理。恶意prompt有多种语言版本,需要做中文适配。公开数据集质量参差不齐,需要进行过滤去重等操作。
- 数据合成:一些新型攻击手段,并没有公开的数据集作为参考(MCP攻击、LLMDoS攻击等),需要进行高质量样本的合成。
目前来看,LLM本身已经具有相应的数据处理、合成能力,可以通过Prompt工程,利用高性能的商用、开源模型进行处理。
数据处理
框架分析
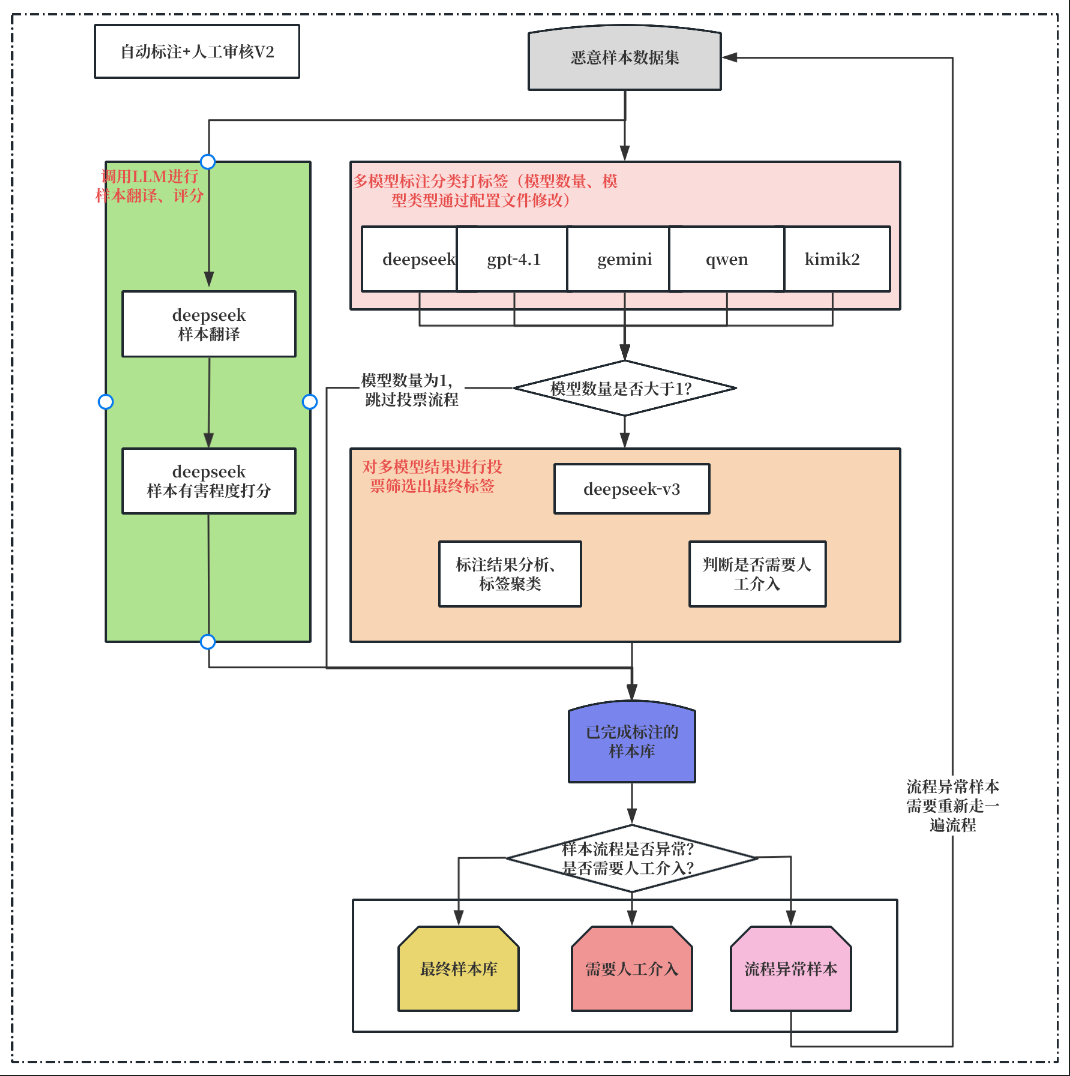
给定恶意prompt,对其进行分类。可以调用大模型进行标注来减少人力成本。具体来说需要实现如下功能
- 翻译 :样本来源可能是公开数据集、真实生产环境数据等。为了适配中文领域,需要对其进行翻译操作。
- 多模型标注: 为了提高标注样本的准确性,可以引入多个模型进行标注,并额外使用一个模型进行聚合,获取最终标签。
- 人工介入:标注模型没有达成共识、样本过长无法处理等情况,需要人工介入来分析。
数据合成
为什么需要数据合成?
无论是模型训练、数据标注都需要数据。实际场景中,大多数prompt都是正常非恶意的,因此从现有生产环境中收集大量真实样本很不现实。这时候就需要进行数据合成。好的数据合成方案可以获取大量高质量、符合目标的prompt。
如何数据合成?
- 分布:我们可以把理想的数据分布看作一个球型。理想的合成数据集应该尽可能均匀分布到球的各个点上。
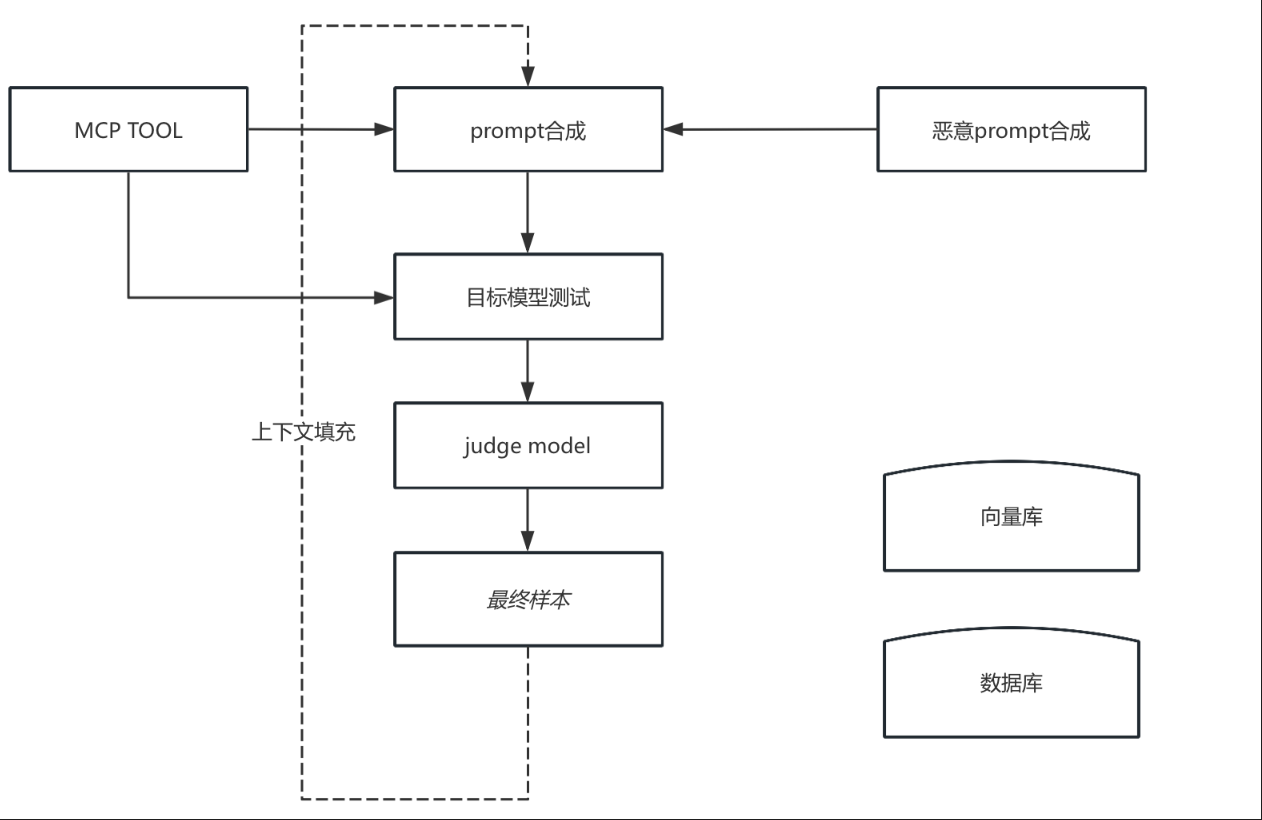
- 方法:现有的LLM具有足够的专业知识,思路是给LLM足够的上下文填充,让其自动化的合成样本。
- 问题:一个固定的prompt发送给模型,其输出大概率是相似的,很明显不满足球型分布的要求。质量低、重复等都是需要解决的问题。
- 方案: 单纯的Workflow解决不了,就需要Agentflow来解决 — 给LLM记忆力(上下文)。让其带着历史的经验进行下一步的合成。 质量低、重复的问题,则需要一些工程方案(向量库、沙箱)来协同解决。
另:大模型安全是与应用同步发展的,从最开始的越狱让大模型输出恶意内容,到RAG+联网引发的上下文污染、指令覆盖,到MCP恶意调用等… 新型的攻击依托于应用,我们可以依据模型的输出来捕获攻击手段,但~很难让大模型自己想出0day(完全没有见过的攻击类型)。因此数据合成并不能一蹴而就。
合成MCP恶意调用数据
文章参考:
博客地址: qwrdxer.github.io
欢迎交流: qq1944270374
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com