DPO
在分析PPO 、GRPO之前,首先分析一下DPO。
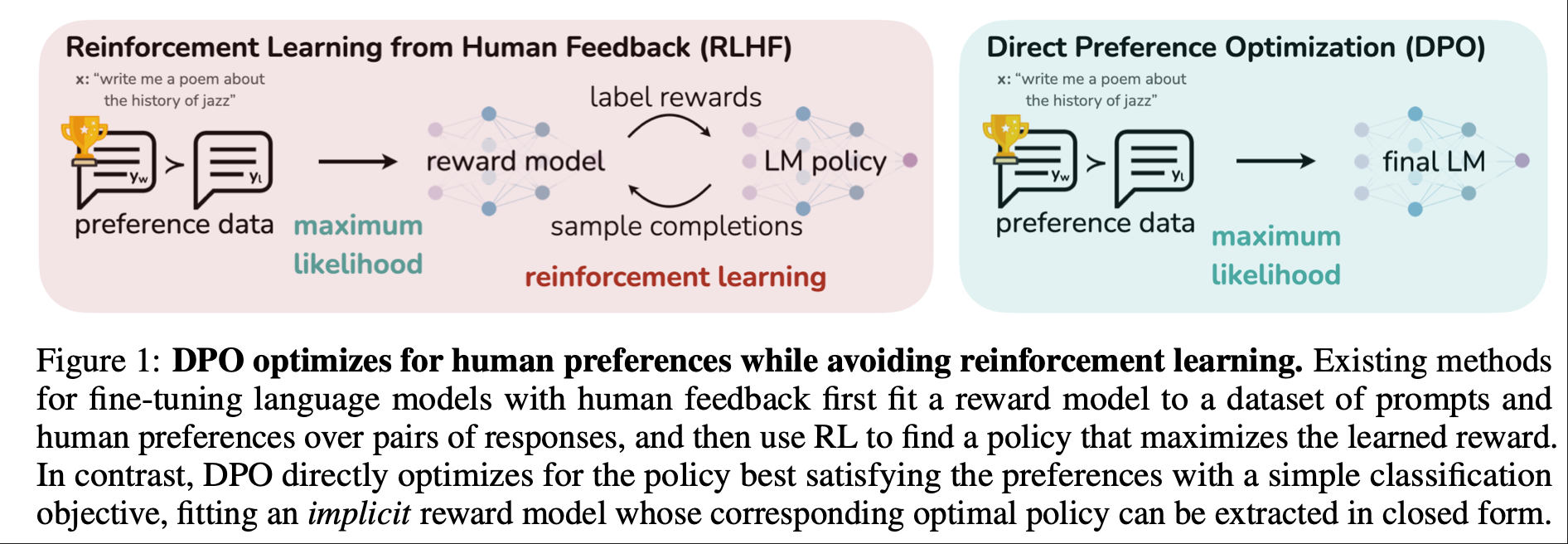
DPO 是“由RL目标推导而来的、但训练过程是监督式的偏好优化方法”。因此实践上常把它归为“RL-free 对齐”,在成本、稳定性与实现复杂度上更友好,同时能获得接近或更好的对齐效果。(ChatGPT生成)
损失函数如下
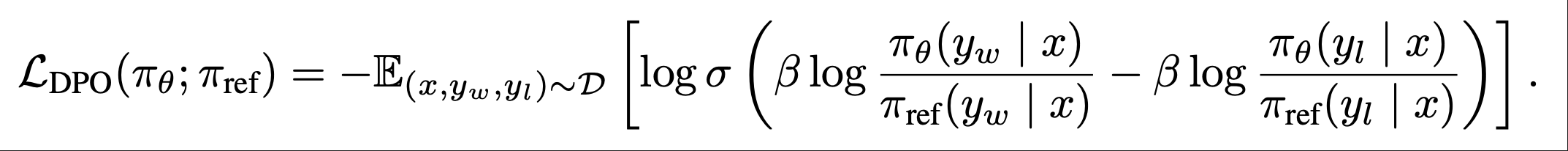
其大概流程是:
- 样本选择 每条样本为 {x,y+,y−}{x,y+,y−}(prompt/问题、被偏好回答、被拒绝回答)。
- 参与模型:初始化2个相同的模型,一个是策略模型,用于训练,一个是参考模型(不进行参数更新),用于约束策略模型更新。
- {prompt ,choose } ,{prompt. reject} 分别发送给2个模型,计算出四次分布
- 计算损失,更新策略模型,核心思想是,让策略模型对给定的prompt,更偏向于输出choose,而不是reject。
我在开始学习时,一个疑惑是:为什么不直接用{prompt ,choose } 去做SFT训练,而是增加了一个模型,增加了一个对比样本{prompt. reject} ? 思考后的总结如下:
- 如果只使用SFT做{prompt. choose}训练,其只能学习到什么是好的,但仍有输出坏的可能性,就像给学生参考答案去学习,不给他说一下”经典错误、标准零分”的情况,它在未来还是有可能犯错误的。 使用2个样本对{prompt ,choose } ,{prompt. reject} 同时更新,鼓励模型生成好的,抑制模型输出坏的。
- DPO 的参考模型等价于在目标里引入对参考分布的 KL 约束,起到“锚定/防漂移、尺度校准、稳定收敛、保留通用能力”的作用;KL 强度(ββ)对效果很敏感
核心代码
# =============== 序列对数概率 ===============
def sequence_logprobs(model, batch, length_normalize: bool = False):
"""
只对 labels != -100 的位置取 log p(token),并按样本求和(或平均)
返回 shape: [B]
"""
out = model(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"]
)
logits = out.logits # [B, T, V]
# 移位对齐:用 t 的logits 预测 t 的label(因 CausalLM 的labels通常右移一位)
# 这里我们直接与 labels[:, 1:] 对齐 logits[:, :-1]
labels = batch["labels"]
logits = logits[:, :-1, :]
labels = labels[:, 1:]
logprobs = F.log_softmax(logits, dim=-1) # [B, T-1, V]
# 选取标签位置的 log p
selected = torch.gather(logprobs, dim=-1, index=labels.unsqueeze(-1)).squeeze(-1) # [B, T-1]
mask = (labels != -100).float()
token_sums = (selected * mask).sum(dim=-1) # [B]
lengths = mask.sum(dim=-1).clamp_min(1.0) # 防止除零
return token_sums / lengths if length_normalize else token_sums
# =============== DPO 步骤 ===============
def dpo_step(policy, ref, batch, beta: float = 0.1, length_normalize: bool = False):
# policy:参与反传;ref:冻结,仅前向
# 1) 策略模型对数概率
lp_pos = sequence_logprobs(policy, batch["chosen"], length_normalize)
lp_neg = sequence_logprobs(policy, batch["rejected"], length_normalize)
# 2) 参考模型对数概率(不求梯度)
with torch.no_grad():
lr_pos = sequence_logprobs(ref, batch["chosen"], length_normalize)
lr_neg = sequence_logprobs(ref, batch["rejected"], length_normalize)
# 3) 构造 z 与 DPO 损失:-log σ(z) == BCEWithLogits(z, 1)
z = beta * ((lp_pos - lp_neg) - (lr_pos - lr_neg))
loss = F.binary_cross_entropy_with_logits(z, torch.ones_like(z))
# 方便监控的统计项
with torch.no_grad():
acc = (z > 0).float().mean() # z>0 即模型偏向 chosen
margin = (lp_pos - lp_neg).mean()
return loss, {"pref_acc": acc.item(), "policy_margin": margin.item(), "logit_mean": z.mean().item()}
参考资料
https://www.bilibili.com/video/BV1JMYbzjEmj
https://arxiv.org/abs/2305.18290
https://zhuanlan.zhihu.com/p/18745659547
PPO
文章参考:
博客地址: qwrdxer.github.io
欢迎交流: qq1944270374
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com