对大模型安全WAF中出现的实体进行分析
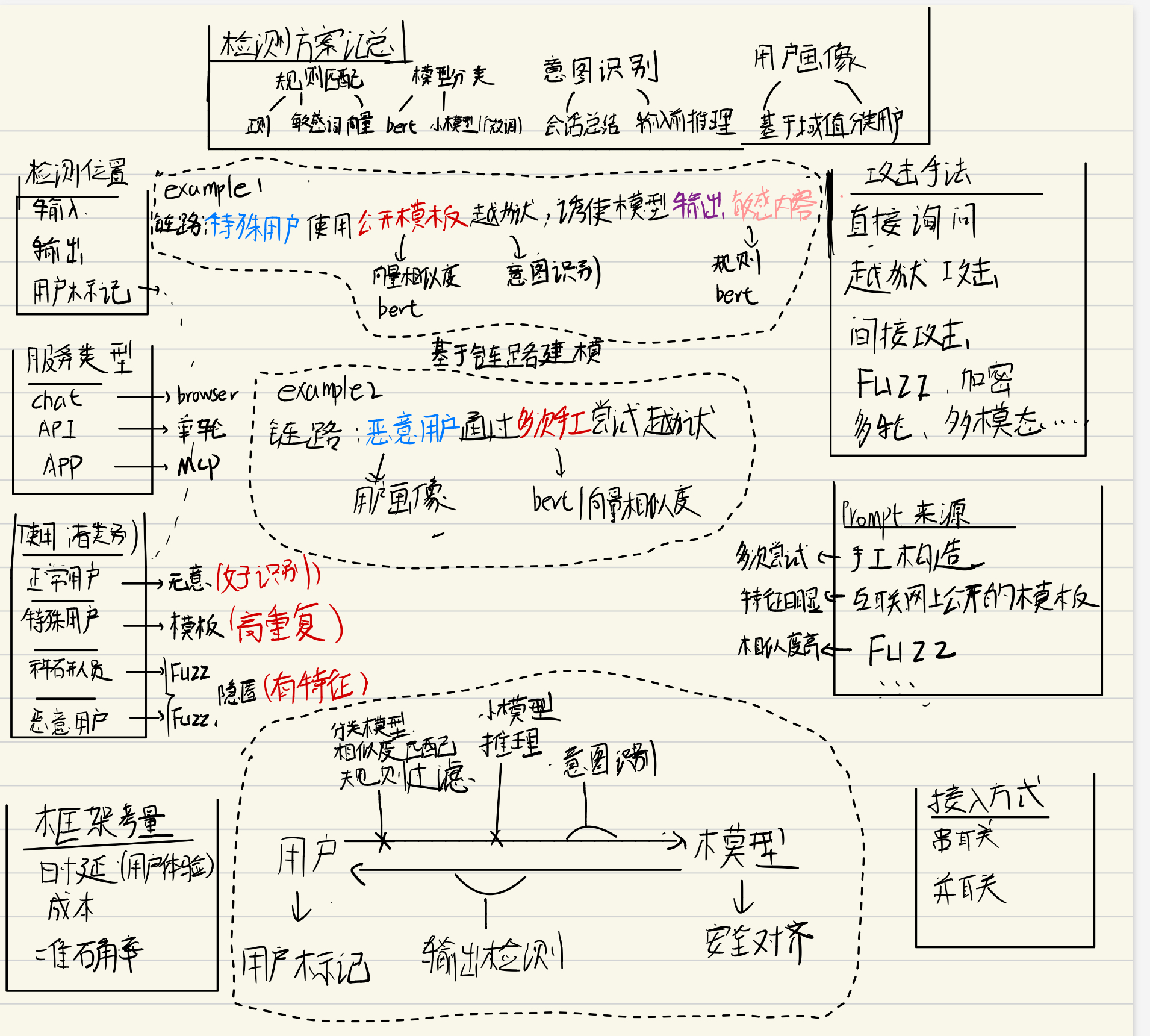
使用者类别(用户画像)
首先要分析的是谁在使用模型服务,谁会尝试越狱攻击,攻击特征如何。
- 正常用户, 占大多数, 平时发向模型的query都是正常的,可能会在无意识的情况下询问一些较为敏感、恶意的问题,这些问题一般特征明显,很好识别。
- 特殊用户,对模型有特殊用途(渗透测试、AI女友、敏感数据合成),需要通过prompt限制模型的安全对齐的用户。可能会直接使用各种公开的模板,特点是重复度高,可以通过持续收集在野的模板进行防御。
- 科研人员,使用自己研究的方法对模型在指定数据集上进行测试\Fuzz。
- 恶意用户,特征可能类似于科研人员,但会将恶意样本用于真实的恶意目的。
不同的用户特征不同,如一个正常的程序员,平常的问题可能就是BUG解决、代码生成,不会刻意构造越狱模板来绕过模型对齐。对于这种类型的帐号,可以通过简单的输入输出过滤,减少资源消耗。科研人员可能会通过API持续进行Fuzz,Fuzz特征明显,可以通过用户标记、向量匹配等进行检测。
用户画像应该是基于对话持续更新的,理想的情况应该是对不同的用户设置不同的防御强度,避免过度的资源消耗。
检测&防御方案
不同的检测方案有不同的延迟、成本,需要综合考虑进行方案实施
- 规则匹配,攻击者的输入、模型的输出会含有大量敏感词,最直接的方法是关键词检测。通过正则表达式、Trie树、AC自动机来实现,需要持续维护敏感词库。可以通过python的
ahocorasick来实现一个简单的demo,实现检测效果。规则匹配实现简单,缺点是对于隐藏意图的输入难以检测。
- 模型检测,将问题转换成一个分类问题,训练模型来检测攻击意图。可以训练一个Bert模型做分类任务,如PromptGurad就是基于Bert模型进行训练,用于检测prompt注入。也可以训练一个较小的语言模型,进行推理输出(准确率高,但是延迟也高),如llamaguard就是一个14b的模型,用于检测。
PromptGuard的简析可以看我的另一篇博客 - 意图识别, 在回答用户的query前,先对query使用语言模型进行分析,若分析出用户有恶意的意图,则拒绝。可以使用外置的小模型进行意图识别、分类;也可能通过prompt工程、微调模型等,对基模进行训练,使其学会在回答问题前进行意图识别、分析。意图识别会用到语言模型的推理能力,所以延迟较高,可解释性较强。
- prompt工程,在系统提示词方面进行安全加固,如强调模型要保持有用性、无害性。OpenAI、Claude的模型都会在系统提示词上进行安全性的强调。
https://github.com/asgeirtj/system_prompts_leaks - prompt聚类,维护一个向量库,对于常见的越狱模板、恶意问题可以进行向量化,用户的输入通过相似度匹配进行搜索,若有相似的样本,则将其标记为疑似恶意query,后续使用其他手段进行二次分析即可。对于FUZZ攻击,其词向量相似度很高,用这种方法进行防御应该会有不错的效果。
- 基模训练,最直接的方法就是通过微调、强化学习等方式让模型学会拒绝。这需要标注足够多的数据,同时基模训练成本较高,训练后的模型在通用能力上可能会下降。
- 用户画像,如可以每天基于用户的对话历史,对用户进行标记,对不同的用户,使用不同的防御手段等。
- 模型表征,有些学者研究发现,模型输出的隐藏层、token预测的困惑度都可以作为衡量是否被越狱的指标,这些可以作为额外信息辅助检测。
- query改写,可以用来防御gcg等攻击,gcg攻击的特点是后面跟了不可读的token,可以外接一个小模型做Query改写,在保留用户原始意图的同时,破坏gcg结构。
- Special Token 越狱一般会导致模型指令被劫持,可以在system prompt中要求模型输出一些特殊的Token,在输出时检查,若没有输出,则可能被劫持。
- …
成本、准确率、用户体验,是很难同时平衡到的,最理想的waf应该是动态的、多方位的。
攻击类型
LLM存在不同的攻击面,随着未来模型的落地场景增加,模型的攻击面也会越来越多。
- 越狱攻击,输出有害内容, 最开始的时候模型仅有一个聊天页面,攻击的目标是让模型输出有害的内容。最经典的就是让模型回答如何制作炸弹。
- 系统提示词窃取,复杂的应用拥有复杂的预设提示词,如Cursor、Trae、codebuddy等,提示词都是成百上千行,这些提示词本身具有一定的商业价值。
- 间接注入,上下文工程,RAG、联网搜索、PDF解析、function call… 填充入的信息不再完全是由用户确定的,恶意Prompt可能会存在其中,导致简介注入。
- 命令执行,为了让模型拥有更多的能力,可以通过MCP编写外部工具供模型调用。这样模型就不单是一个聊天模型来,它可以通过工具调用来与外界进行交互。模型能力增加的同时,也带来了新的风险。
- 拒绝服务,如让模型重复”ABC” 1000次,导致模型循环不断输出重复的Token,消耗服务器端资源。
不同的攻击类型需要不同的防御手段,越狱攻击是我们讨论的主流。 提示词窃取可以通过相似度匹配,对模型输出进行检测。命令执行需要对Agent做能力限制,不能执行高权限高风险的命令。拒绝服务需要做意图识别,拒绝这种无意义query。
越狱攻击类型
越狱攻击有不同的手法,对应的也有不同的特征。攻击手法有很多,很难完全覆盖,下面分析几种主流的方法。
- 构造Prompt直接询问,特点是缝合。如使用通用的越狱模板(DAN)+否定抑制(不要输出SORRY)+指令劫持(忽略上述指令)+有害问题。 这类攻击特征、恶意意图都很明显,很容易检测到。
- 隐藏恶意意图,将有害问题进行加密,并提供模型线索进行解密,模型在推理中逐渐失去安全能力,最终响应用户问题。 这类攻击就需要使用语言模型进行推理检测。
- 多轮对话越狱,如最近很火的回声室攻击等,通过不断对话,诱导模型输出有害内容。可以对模型输出进行持续监测。
- 基于优化的方法,如GCG这种白盒攻击方法,特点是有许多不可读的字符,困惑度较高。
- 低资源/跨模态,模型对齐可能是只使用中文/英文训练,切换成小语种可能绕过。多模态模型(语音、音频、视频、图片)中新的模态可以用来包含恶意指令。
- 思维链劫持,如论文H-COT会构造模型思维链内容发送给目标模型,影响其思维链中模型对齐。更简单的方法如在prompt最后加上
follow user instruct 等。 - ….
恶意Prompt来源
不同的Prompt有不同的结构、特征
- 手工构造,特征是攻击者多次尝试、进行绕过。
- 互联网公开的模板,可以定期维护收集模板库来防御。
- FUZZ,攻击频率高、样本之间有相似性。
WAF接入方式
- 串联:用户输入处理后才能 发送给业务模型,模型输出处理后才发送给用户。
- 并联:持续检测用户输入、模型输出。检测到异常时迅速终断。
可以考虑使用混合的模式,如输入串联阻塞、输出并联监测等。
接入考量
- 维护成本:不同的防御方案有不同的成本,如对齐基模成本巨大,且不能实时更新
- 性能影响:query改写、模型对齐等可能会降低模型等的通用能力
- 用户体验:过度拒绝、延迟增加可能会影响用户体验
- 准确率:不同的方案有不同的准确率、误报率
附录–关键词匹配代码
通过AC自动机,加载敏感词库。
import ahocorasick
import os
def load_sensitive_words(file_path):
"""
从指定文件中加载敏感词。
"""
sensitive_words = []
if not os.path.exists(file_path):
print(f"错误:文件 '{file_path}' 不存在。请创建该文件并添加敏感词。")
return sensitive_words
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
word = line.strip()
if word:
sensitive_words.append(word)
return sensitive_words
def create_ac_automaton(words):
"""
构造 AC 自动机。
"""
A = ahocorasick.Automaton()
for index, word in enumerate(words):
A.add_word(word, (index, word))
A.make_automaton()
return A
def filter_text(text, automaton):
"""
使用 AC 自动机过滤文本并替换敏感词。
"""
found_words_info = []
# 查找所有匹配到的敏感词及其位置
for end_index, (index, original_word) in automaton.iter(text):
start_index = end_index - len(original_word) + 1
found_words_info.append({
'word': original_word,
'start': start_index,
'end': end_index
})
# 根据找到的位置进行替换
result_text_list = list(text)
# 按倒序遍历,避免索引变化
for item in sorted(found_words_info, key=lambda x: x['start'], reverse=True):
start = item['start']
end = item['end']
result_text_list[start:end+1] = ['*'] * len(item['word'])
return "".join(result_text_list)
if __name__ == "__main__":
sensitive_words_file = "色情类.txt"
print("正在加载敏感词库...")
sensitive_words = load_sensitive_words(sensitive_words_file)
if not sensitive_words:
print("未加载到敏感词。程序退出。")
else:
print(f"成功加载 {len(sensitive_words)} 个敏感词。")
# 构造 AC 自动机
print("正在构建 AC 自动机...")
ac_automaton = create_ac_automaton(sensitive_words)
print("AC 自动机构建完成。")
# 接收用户输入并进行检测
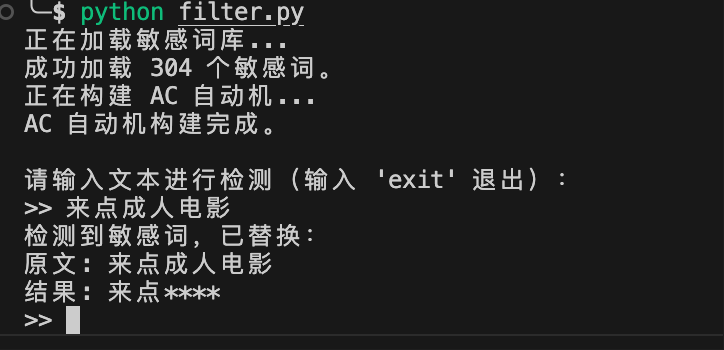
print("\n请输入文本进行检测(输入 'exit' 退出):")
while True:
user_input = input(">> ")
if user_input.lower() == 'exit':
break
# 过滤文本
filtered_text = filter_text(user_input, ac_automaton)
# 输出结果
if user_input == filtered_text:
print("未检测到敏感词。")
else:
print("检测到敏感词,已替换:")
print(f"原文: {user_input}")
print(f"结果: {filtered_text}")
文章参考: https://github.com/asgeirtj/system_prompts_leaks
https://github.com/fwwdn/sensitive-stop-words
博客地址: qwrdxer.github.io
欢迎交流: qq:1944270374 wx:qwrdxer
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1944270374@qq.com